Ưu và Nhược điểm của KNN
Mặc dù đơn giản và trực quan, KNN cũng có những hạn chế đáng kể cần được cân nhắc kỹ lưỡng khi lựa chọn thuật toán cho một bài toán cụ thể. Bảng 2: Tóm… Ưu và Nhược điểm của KNN
Mặc dù đơn giản và trực quan, KNN cũng có những hạn chế đáng kể cần được cân nhắc kỹ lưỡng khi lựa chọn thuật toán cho một bài toán cụ thể. Bảng 2: Tóm… Ưu và Nhược điểm của KNN
Việc lựa chọn thuật toán học máy phù hợp là một quyết định quan trọng, phụ thuộc vào đặc điểm của dữ liệu và yêu cầu cụ thể của bài toán. KNN, với tính đơn… So sánh KNN với các thuật toán học máy khác
Kiến trúc Transformer lần đầu tiên được giới thiệu trong bài báo mang tính bước ngoặt năm 2017 “Attention Is All You Need” của các nhà nghiên cứu Google. Bài báo này đánh dấu một… Transformers và các Cải tiến
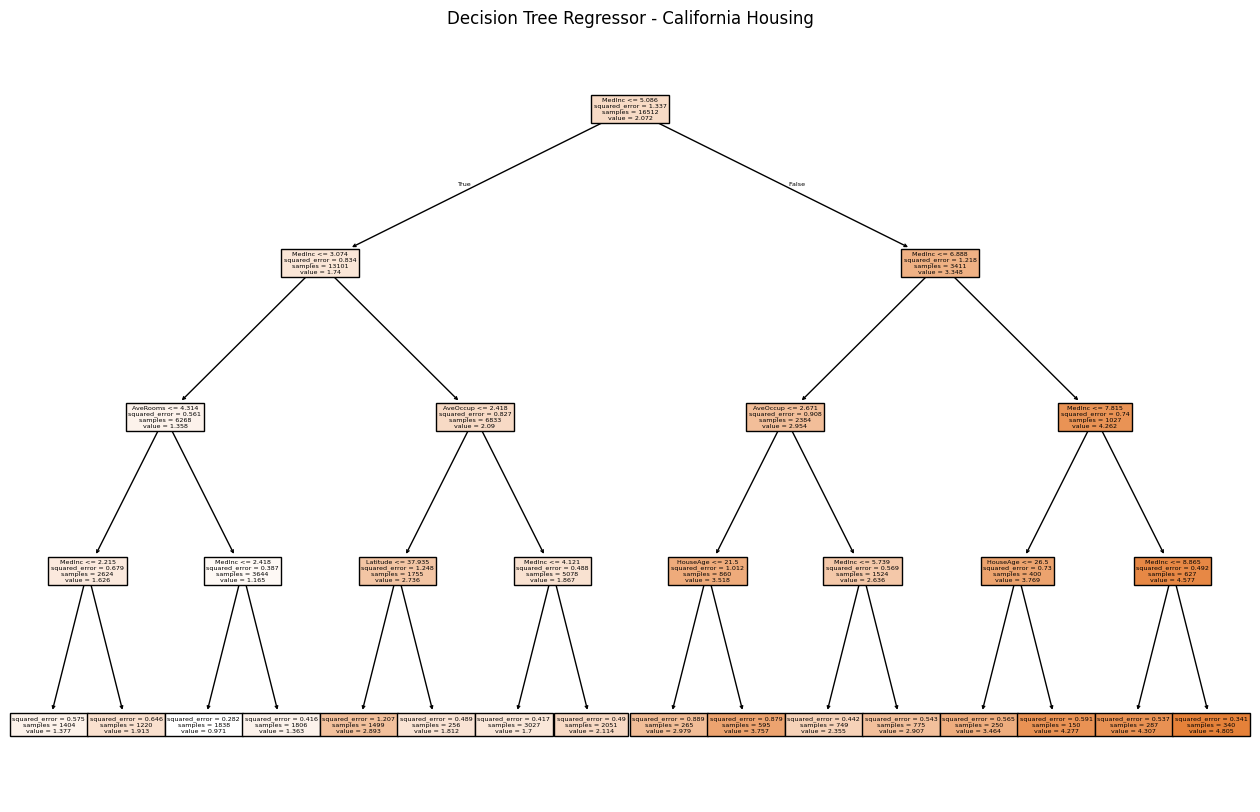
🍀 Ví dụ cây quyết định hồi quy (Decision Tree Regression) với Python: khi bài toán không phải phân loại mà là dự đoán giá trị số (như giá nhà, nhiệt độ…). Dưới đây là… Ví dụ cây quyết định hồi quy (Decision Tree Regression) với Python
Hồi quy Elastic Net – nghe tên đã thấy “đàn hồi”, đúng không? Nó kết hợp sức mạnh của cả hai cao bồi Lasso và nhạc trưởng Ridge để tạo ra một mô hình vừa… Hồi quy Elastic Net
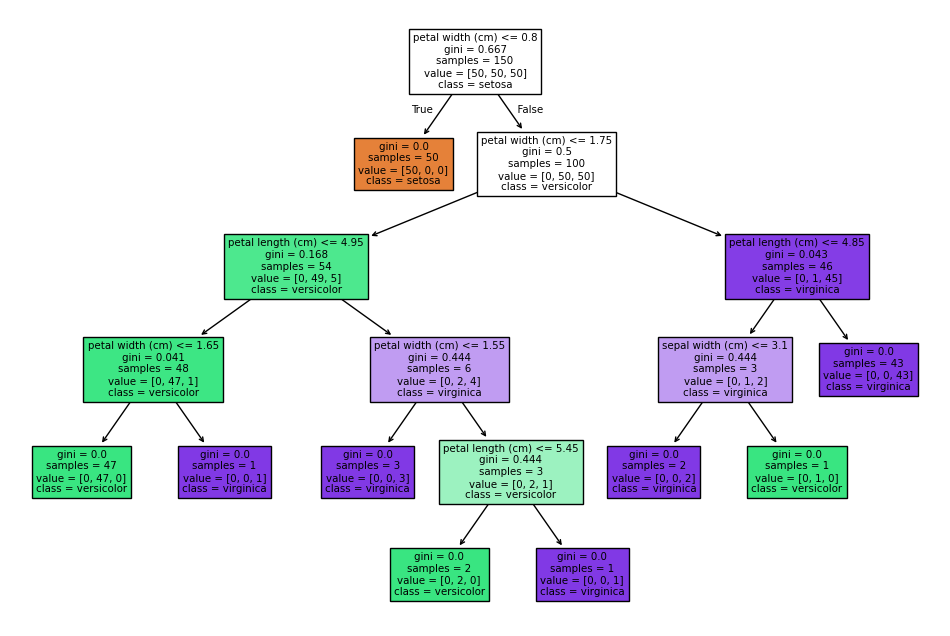
🌳 Cây Quyết Định (Decision Tree) là một thuật toán học máy phổ biến dùng để phân loại hoặc hồi quy. Nó hoạt động bằng cách chia dữ liệu thành các nhánh dựa trên điều… Ví dụ: Cây Quyết Định (Decision Tree) cho bài toán phân loại trong Python
Mạng đối nghịch tạo sinh (GANs) đại diện cho một bước đột phá mang tính cách mạng trong lĩnh vực học sâu, thiết lập một khuôn khổ độc đáo để tạo ra dữ liệu tổng… Một số loại mô hình tạo sinh GAN tiêu biểu

MONAI (Medical Open Network for AI) là một khung nền mã nguồn mở, được cộng đồng hỗ trợ, chuyên biệt cho học sâu trong hình ảnh y tế. Mục đích chính của nó là tăng… MONAI: Một Khung Nền Toàn Diện cho Học Sâu trong Xử Lý Ảnh Y Tế
Trong ví dụ này, chúng ta sẽ sử dụng thuật toán K-Nearest Neighbors (KNN) để phân loại hoa từ tập dữ liệu Iris. Dưới đây là phần giải thích chi tiết từng bước: 📦 1.… K-Nearest Neighbors (KNN) trong R
Học tăng cường giống như dạy một chú cún bằng bánh quy: làm đúng thì thưởng, làm sai thì không có bánh! 😄 Nó tự tìm ra cách làm tốt nhất qua hàng loạt lần… Học tăng cường
Bias và Variance là gì? Trong máy học, bias và variance là hai nguồn chính gây ra sai số trong dự đoán của mô hình. Chúng phản ánh cách mô hình khớp với dữ liệu… Bias và Variance trade off (cân bằng giữa độ chệch và phương sai) là gì?
Nhiễu dữ liệu (data noise) là các sai lệch, lỗi hoặc thông tin không chính xác, không liên quan trong tập dữ liệu, làm giảm chất lượng dữ liệu và ảnh hưởng đến hiệu quả… Nhiễu dữ liệu
Phân cụm K-Means là một thuật toán học máy không giám sát được sử dụng rộng rãi, được thiết kế để nhóm các điểm dữ liệu chưa được gán nhãn vào các nhóm hoặc cụm… Ứng dụng Thực tế của Thuật toán Phân cụm K-Means trong Phân tích Dữ liệu và Kinh doanh
Học máy (Machine Learning – ML) là một lĩnh vực chuyên sâu của trí tuệ nhân tạo (AI), tập trung vào việc nghiên cứu và phát triển các kỹ thuật cho phép hệ thống tự… Ứng Dụng Học Máy Trong Phân Tích Khách Hàng: Tối Ưu Hóa Chiến Lược Kinh Doanh Trong Kỷ Nguyên Dữ Liệu
SVM là một thuật toán mạnh mẽ, nhưng việc hiểu vị trí của nó so với các thuật toán học máy khác là rất quan trọng để lựa chọn mô hình phù hợp cho một… So sánh SVM với các Thuật toán Học máy Khác