
Trong bài đăng này, chúng ta sẽ nói về phương pháp chưng cất tri thức dựa trên đặc trưng. Một trong những bài báo tiên phong là “FitNets: Hints for Thin Deep Nets” (FitNets: Gợi ý cho các Mạng Lưới Sâu và Mỏng) của Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta & Yoshua Bengio. Ý tưởng chính của bài báo này là giới thiệu một phương pháp huấn luyện mới gọi là FitNets. Phương pháp này nén các mạng nơ-ron “giáo viên” (teacher) lớn và rộng thành các mạng lưới “học sinh” (student) nhỏ hơn, sâu hơn và mỏng hơn. Vấn đề cốt lõi mà bài báo giải quyết là mặc dù các mạng lưới sâu rất mạnh mẽ, việc huấn luyện chúng rất khó khăn. Điều này đặc biệt đúng với các mạng vừa rất sâu vừa “mỏng” (nghĩa là chúng có ít tham số hơn nhiều trong các tầng của mình).
Giải pháp của bài báo là mở rộng khái niệm Chưng cất Tri thức (Knowledge Distillation – KD).
KD tiêu chuẩn bao gồm việc huấn luyện một mạng lưới học sinh nhỏ để bắt chước các đầu ra “mềm” (soft outputs) cuối cùng (các xác suất) của một mạng lưới giáo viên lớn đã được huấn luyện trước.
FitNets mở rộng điều này bằng cách sử dụng không chỉ đầu ra cuối cùng của giáo viên mà còn cả các tầng ẩn trung gian của nó làm “gợi ý” để hướng dẫn quá trình huấn luyện của học sinh.
Việc “huấn luyện dựa trên gợi ý” này hoạt động như một hình thức tiền huấn luyện, hướng dẫn mạng lưới học sinh vào một điểm khởi đầu tốt, điều này làm cho nhiệm vụ khó khăn là huấn luyện một mạng lưới rất sâu và mỏng trở nên khả thi.
🧠 Cách FitNets hoạt động: Quy trình Hai Giai đoạn
Phương pháp huấn luyện FitNet được chia thành hai giai đoạn chính, như được trình bày trong Hình 1 của bài báo:
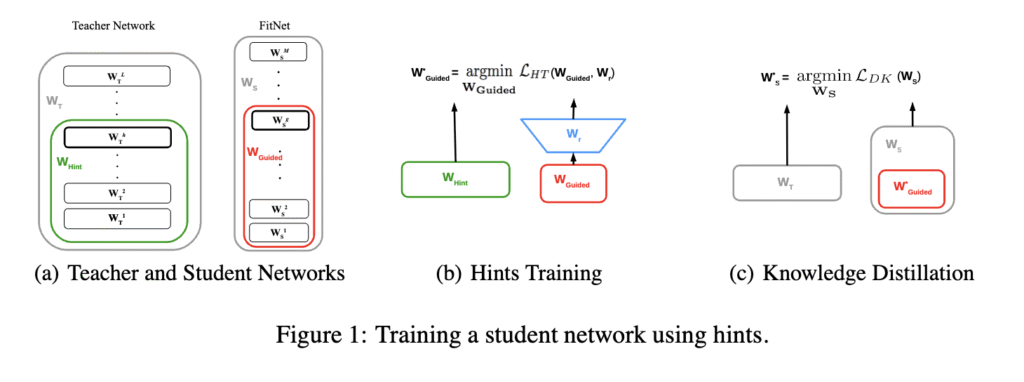
Giai đoạn 1: Huấn luyện Dựa trên Gợi ý (Hình 1b)
Giai đoạn này tiền huấn luyện nửa đầu của mạng lưới học sinh.
Chọn Tầng: Một “tầng gợi ý” (hint layer) (thường là một tầng ở giữa) được chọn từ mạng lưới giáo viên lớn. Một “tầng được hướng dẫn” (guided layer) tương ứng được chọn trong mạng lưới học sinh mỏng.
Thêm Bộ hồi quy (Regressor): Vì mạng học sinh mỏng hơn, tầng được hướng dẫn của nó nhỏ hơn (có ít đầu ra hơn) so với tầng gợi ý của giáo viên. Để làm cho chúng có thể so sánh được, một mạng lưới hồi quy nhỏ được gắn vào tầng được hướng dẫn của học sinh để mở rộng đầu ra của nó cho khớp với kích thước của tầng gợi ý của giáo viên.
Huấn luyện: Các tham số của nửa đầu mạng lưới học sinh (cho đến tầng được hướng dẫn) và bộ hồi quy được huấn luyện để làm cho đầu ra được hướng dẫn của học sinh khớp với đầu ra gợi ý của giáo viên.
Giai đoạn ban đầu này thực chất buộc các tầng đầu tiên của học sinh phải học các biểu diễn trung gian tương tự như giáo viên, cung cấp một “gợi ý” quan trọng giúp mạng lưới dễ tối ưu hóa hơn.
Giai đoạn 2: Chưng cất Tri thức (Hình 1c)
Sau khi Giai đoạn 1 hoàn tất, bộ hồi quy được loại bỏ. Toàn bộ mạng lưới học sinh (sử dụng các tham số đã được tiền huấn luyện từ Giai đoạn 1 cho nửa đầu của nó) sau đó được huấn luyện bằng hàm mất mát Chưng cất Tri thức tiêu chuẩn.
Hàm mất mát này huấn luyện học sinh thực hiện đồng thời hai việc:
Khớp với các nhãn thật của dữ liệu (huấn luyện phân loại tiêu chuẩn).
Khớp với các đầu ra đã được làm mềm (phân phối xác suất của giáo viên) từ tầng cuối cùng của mạng lưới giáo viên.
🏆 Kết quả
Bằng cách sử dụng quy trình hai giai đoạn, dựa trên gợi ý này, các tác giả đã có thể huấn luyện thành công các mạng lưới rất sâu và mỏng mà các phương pháp tiêu chuẩn (như lan truyền ngược hoặc thậm chí KD thông thường) không thể huấn luyện hiệu quả.
Độ nén cao: Ví dụ, trên bộ dữ liệu CIFAR-10, học sinh FitNet vượt trội hơn giáo viên của nó (độ chính xác 91.61% so với 90.18%) trong khi có số lượng tham số ít hơn 10.4 lần.
Nhanh và Hiệu quả: Bản chất “mỏng” của các mạng lưới có nghĩa là chúng yêu cầu ít tính toán hơn đáng kể và nhanh hơn nhiều vào thời gian suy luận (inference time).
Tóm lại, FitNets cung cấp một cách để có được lợi ích về hiệu suất của độ sâu trong khi vẫn duy trì tốc độ và hiệu quả của một mô hình mỏng, nhỏ gọn.
Ví dụ trên MNIST
Trong đoạn mã sau, chúng ta sẽ triển khai chưng cất tri thức dựa trên đặc trưng. Tuy nhiên, chúng ta sẽ không tuân theo thuật toán huấn luyện theo giai đoạn cụ thể vốn là đề xuất chính của bài báo để giúp các mạng lưới rất sâu và mỏng huấn luyện thành công, bởi vì chúng ta thực sự sẽ huấn luyện một mạng không quá sâu cho MNIST làm ví dụ. Tuy nhiên, mã có thể dễ dàng được điều chỉnh theo kiểu huấn luyện của FitNets
Một lần nữa, ví dụ cụ thể này sử dụng hai loại tri thức:
Chưng cất Logit (Logit Distillation): Học sinh học từ các xác suất đầu ra cuối cùng của giáo viên (các “nhãn mềm”).
Chưng cất Đặc trưng (Feature Distillation): Học sinh cũng học cách bắt chước các bản đồ đặc trưng trung gian (biểu diễn nội bộ) của giáo viên.
Python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
Imports (Các thư viện nhập vào)
Khối này nhập tất cả các thư viện cần thiết từ PyTorch.
torch: Thư viện PyTorch cốt lõi.torch.nn: Chứa các khối xây dựng cho mạng nơ-ron (các tầng, mô hình, hàm mất mát).torch.nn.functional(as F): Cung cấp các hàm phổ biến như hàm kích hoạt (ví dụ:relu) và hàm mất mát (ví dụ:cross_entropy).torch.optim: Chứa các thuật toán tối ưu hóa như SGD.torchvision: Một gói cho thị giác máy tính bao gồm các bộ dữ liệu phổ biến (như MNIST) và các phép biến đổi hình ảnh.- torch.utils.data.DataLoader: Một tiện ích để dễ dàng tải, tạo lô (batch) và xáo trộn dữ liệu.
# --- 1. Settings and Hyperparameters ---
# --- 1. Cài đặt và Siêu tham số ---
# Training settings
# Cài đặt huấn luyện
BATCH_SIZE = 64
EPOCHS_TEACHER = 5
EPOCHS_STUDENT = 10
LEARNING_RATE = 0.01
MOMENTUM = 0.9
# Knowledge Distillation (KD) settings
# Cài đặt Chưng cất Tri thức (KD)
TEMPERATURE = 10 # Temperature for softening probabilities
# Nhiệt độ để làm mềm xác suất
ALPHA = 0.1 # Weight for the "hard" (true label) loss. (1-ALPHA) is for the "soft" (logit) loss.
# Trọng số cho mất mát "cứng" (nhãn thật). (1-ALPHA) là cho mất mát "mềm" (logit).
GAMMA = 1.0 # Weight for the "feature" (latent) loss.
# Trọng số cho mất mát "đặc trưng" (tiềm ẩn).
# Set device
# Thiết lập thiết bị
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
- Cài đặt và Siêu tham số
Phần này định nghĩa tất cả các biến cấu hình chính cho thí nghiệm.
- Huấn luyện Tiêu chuẩn:
BATCH_SIZE,LEARNING_RATE, vàMOMENTUMlà các cài đặt tiêu chuẩn cho trình tối ưu hóa SGD. Mô hình giáo viên được huấn luyện trong 5 epochs, và các mô hình học sinh được huấn luyện trong 10 epochs. - Chưng cất Tri thức (KD):
TEMPERATURE(Nhiệt độ): Đây là một tham số KD quan trọng. Khi áp dụng cho các logits trước hàm softmax, nhiệt độ cao hơn (T > 1) sẽ “làm mềm” phân phối xác suất. Điều này khuyến khích học sinh học các mối quan hệ tinh tế giữa các lớp mà giáo viên đã học được (ví dụ: “số ‘7’ này trông hơi giống số ‘1’”).ALPHA: Tham số này kiểm soát sự cân bằng giữa hai loại mất mát.ALPHAnhỏ (như 0.1) có nghĩa là mất mát cuối cùng là 10% từ mất mát “cứng” (học sinh so với nhãn thật) và 90% từ mất mát “mềm” (học sinh so với logits của giáo viên).GAMMA: Đây là trọng số cho hàm mất mát mới trong kịch bản này: mất mát đặc trưng. Nó kiểm soát mức độ học sinh bị phạt vì có các đặc trưng trung gian khác với giáo viên.
- Thiết bị (Device): Mã này kiểm tra xem có GPU hỗ trợ CUDA hay không và chọn nó (“cuda”); nếu không, nó mặc định sửdụng CPU (“cpu”).
# --- 2. Data Loading (MNIST) ---
# --- 2. Tải Dữ liệu (MNIST) ---
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
- Tải Dữ liệu (MNIST)Khối này chuẩn bị bộ dữ liệu chữ số viết tay MNIST.
transform: Định nghĩa một chuỗi các bước tiền xử lý.transforms.ToTensor(): Chuyển đổi hình ảnh PIL đầu vào thành PyTorch Tensors.transforms.Normalize((0.1307,), (0.3081,)): Chuẩn hóa các giá trị pixel của tensor. Các số (0.1307, 0.3081) là giá trị trung bình và độ lệch chuẩn đã được tính toán trước của bộ dữ liệu MNIST.
datasets.MNIST: Tải xuống (nếu chưa có) và tải các tập huấn luyện và kiểm tra, áp dụngtransformcho mỗi hình ảnh.- DataLoader: Bao bọc các bộ dữ liệu. Tiện ích này sẽ cung cấp dữ liệu cho các mô hình theo từng lô (BATCH_SIZE) và sẽ xáo trộn dữ liệu huấn luyện (shuffle=True) ở mỗi epoch để cải thiện khả năng tổng quát hóa.
# --- 3. Model Definitions (Updated) ---
# --- 3. Định nghĩa Mô hình (Đã cập nhật) ---
class TeacherNet(nn.Module):
"""Teacher model now returns final logits AND intermediate features."""
"""Mô hình Giáo viên (Teacher) giờ đây trả về logits cuối cùng VÀ các đặc trưng trung gian."""
def __init__(self):
super(TeacherNet, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(64 * 7 * 7, 256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
# --- Extract intermediate features ---
# --- Trích xuất các đặc trưng trung gian ---
# These are the features we will force the student to mimic
# Đây là những đặc trưng chúng ta sẽ buộc học sinh bắt chước
features = self.pool(F.relu(self.conv2(x))) # Shape: [B, 64, 7, 7]
# Kích thước: [Lô, 64, 7, 7]
x_flat = features.view(-1, 64 * 7 * 7) # Flatten
# Làm phẳng
x = F.relu(self.fc1(x_flat))
logits = self.fc2(x) # Output raw logits
# Trả về logits thô
return logits, features
Định nghĩa Mô hình: TeacherNet
Phần này định nghĩa mô hình “Giáo viên” (Teacher) lớn và phức tạp. Nó là một Mạng Nơ-ron Tích chập (CNN) tiêu chuẩn với một sửa đổi quan trọng.
- Kiến trúc: Nó có hai tầng tích chập (
conv1với 32 bộ lọc,conv2với 64 bộ lọc) theo sau là hai tầng kết nối đầy đủ (fc1với 256 đơn vị ẩn,fc2xuất ra 10 điểm số lớp). - Phương thức
forward: Điều này định nghĩa luồng dữ liệu.- Thay đổi chính là thay vì chỉ trả về
logitscuối cùng, mô hình này cũng trả về các đặc trưng trung gian (features) từ sau khối tích chập thứ hai. - Tensor features này (kích thước [Batch, 64, 7, 7]) đại diện cho “sự hiểu biết” của giáo viên về hình ảnh ở mức độ sâu, và nó sẽ được sử dụng để huấn luyện học sinh.
- Thay đổi chính là thay vì chỉ trả về
class StudentNet(nn.Module):
"""Student model now includes a 'feature adapter' and returns adapted features."""
"""Mô hình Học sinh (Student) giờ đây bao gồm một 'bộ điều hợp đặc trưng' và trả về các đặc trưng đã được điều hợp."""
def __init__(self):
super(StudentNet, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# --- Feature Adapter ---
# --- Bộ điều hợp Đặc trưng ---
# This module's job is to transform the student's features
# (16 channels, 14x14) into the teacher's feature shape (64 channels, 7x7).
# Nhiệm vụ của mô-đun này là biến đổi các đặc trưng của học sinh
# (16 kênh, 14x14) thành hình dạng đặc trưng của giáo viên (64 kênh, 7x7).
self.feature_adapter = nn.Sequential(
nn.Conv2d(16, 64, kernel_size=1), # 1x1 conv to match channels
# tích chập 1x1 để khớp số kênh
nn.AdaptiveAvgPool2d((7, 7)) # Avg pool to match spatial dimensions
# Gộp trung bình thích ứng để khớp chiều không gian
)
self.fc1 = nn.Linear(16 * 14 * 14, 32) # FC layer still uses the original 14x14 features
# Tầng FC vẫn sử dụng các đặc trưng 14x14 gốc
self.fc2 = nn.Linear(32, 10)
def forward(self, x):
# --- Student's base features ---
# --- Các đặc trưng cơ sở của Học sinh ---
x_conv = self.pool(F.relu(self.conv1(x))) # Shape: [B, 16, 14, 14]
# Kích thước: [Lô, 16, 14, 14]
# --- Adapt features for comparison ---
# --- Điều hợp các đặc trưng để so sánh ---
features_adapted = self.feature_adapter(x_conv) # Shape: [B, 64, 7, 7]
# Kích thước: [Lô, 64, 7, 7]
# --- Continue to classification ---
# --- Tiếp tục đến phần phân loại ---
x_flat = x_conv.view(-1, 16 * 14 * 14) # Flatten original features
# Làm phẳng các đặc trưng gốc
x = F.relu(self.fc1(x_flat))
logits = self.fc2(x) # Output raw logits
# Trả về logits thô
return logits, features_adapted
- Định nghĩa Mô hình: StudentNet
Phần này định nghĩa mô hình “Học sinh” (Student) nhỏ và đơn giản.
- Kiến trúc: Nó nhỏ hơn nhiều so với giáo viên: chỉ có một tầng tích chập (
conv1với 16 bộ lọc) và các tầng kết nối đầy đủ nhỏ hơn (fc1với 32 đơn vị ẩn). feature_adapter(Bộ điều hợp Đặc trưng): Đây là phần quan trọng nhất. Các đặc trưng nội bộ của học sinh (x_conv) có kích thước[B, 16, 14, 14], khác với các đặc trưng của giáo viên ([B, 64, 7, 7]). Chúng ta không thể so sánh trực tiếp chúng.feature_adapterlà một mạng lưới nhỏ mà công việc duy nhất của nó là biến đổi các đặc trưng của học sinh thành hình dạng đặc trưng của giáo viên.nn.Conv2d(16, 64, kernel_size=1): Một tích chập 1×1 thay đổi số lượng kênh từ 16 lên 64.nn.AdaptiveAvgPool2d((7, 7)): Thao tác này buộc thay đổi kích thước các chiều không gian từ 14×14 xuống còn 7×7.
- Phương thức
forward:- Nó tính toán các đặc trưng nội bộ của riêng mình (
x_conv). - Nó cho
x_convđi quafeature_adapterđể nhận đượcfeatures_adapted. - Nó sử dụng
x_convgốc để tiếp tục con đường phân loại của riêng mình để tạo ralogits. - Nó trả về cả logits (cho mất mát logit) và features_adapted (cho mất mát đặc trưng).
- Nó tính toán các đặc trưng nội bộ của riêng mình (
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
- count_parameters: Đây là một hàm trợ giúp đơn giản. Nó lặp qua tất cả các tham số (trọng số và độ lệch) trong một mô hình và tính tổng số lượng phần tử, cho ra tổng số tham số có thể huấn luyện. Điều này được sử dụng để cho thấy học sinh nhỏ hơn giáo viên bao nhiêu.
# --- 4. Standard Training and Evaluation (Updated) ---
# --- 4. Huấn luyện và Đánh giá Tiêu chuẩn (Đã cập nhật) ---
def train_standard(model, train_loader, optimizer, epoch):
"""Standard training loop (now ignores the second model output)."""
"""Vòng lặp huấn luyện tiêu chuẩn (bây giờ bỏ qua đầu ra thứ hai của mô hình)."""
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# Models now return (logits, features). We only need logits here.
# Các mô hình giờ trả về (logits, features). Chúng ta chỉ cần logits ở đây.
output, _ = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
print(f"Train Epoch: {epoch} \tLoss: {loss.item():.6f}")
def evaluate(model, test_loader):
"""Standard evaluation loop (now ignores the second model output)."""
"""Vòng lặp đánh giá tiêu chuẩn (bây giờ bỏ qua đầu ra thứ hai của mô hình)."""
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
# Models now return (logits, features). We only need logits here.
# Các mô hình giờ trả về (logits, features). Chúng ta chỉ cần logits ở đây.
output, _ = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'Test set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)')
return accuracy
- Huấn luyện và Đánh giá Tiêu chuẩn
Đây là các hàm để huấn luyện một mô hình “từ đầu” (tức là không có giáo viên).
train_standard: Một vòng lặp huấn luyện bình thường. Nó lặp quatrain_loader, nhận các dự đoán của mô hình, tính toán mất mát cross-entropy tiêu chuẩn (dự đoán sai lệch bao nhiêu so với nhãntargetthật), và cập nhật trọng số mô hình (optimizer.step()).evaluate: Một vòng lặp kiểm tra bình thường. Nó lặp quatest_loader, tính toán tổng mất mát, và đếm số lượng dự đoán đúng để báo cáo độ chính xác.with torch.no_grad()được sử dụng để vô hiệu hóa việc tính toán gradient, tiết kiệm bộ nhớ và thời gian.- Cập nhật chính: Cả hai hàm đều sử dụng output, _ = model(data). Điều này giải nén bộ (logits, features) được trả về bởi các mô hình và loại bỏ các đặc trưng (gán chúng cho _) vì huấn luyện tiêu chuẩn chỉ quan tâm đến đầu ra cuối cùng (logits).
# --- 5. Knowledge Distillation Loss and Training ---
# --- 5. Mất mát Chưng cất Tri thức và Huấn luyện ---
def distillation_loss(
student_logits,
labels,
teacher_logits,
student_features,
teacher_features,
T,
alpha,
gamma
):
"""
Calculates the *combined* knowledge distillation loss.
Now includes:
1. Hard Loss (Cross-Entropy)
2. Soft Loss (KL Divergence on logits)
3. Feature Loss (MSE on feature maps)
"""
"""
Tính toán mất mát chưng cất tri thức *kết hợp*.
Bây giờ bao gồm:
1. Mất mát Cứng (Cross-Entropy)
2. Mất mát Mềm (Phân kỳ KL trên logits)
3. Mất mát Đặc trưng (MSE trên các bản đồ đặc trưng)
"""
# 1. Soft Loss (Logit Distillation)
# 1. Mất mát Mềm (Chưng cất Logit)
soft_loss = nn.KLDivLoss(reduction='batchmean', log_target=True)(
F.log_softmax(student_logits / T, dim=1),
F.softmax(teacher_logits / T, dim=1) # Note: A more standard target here would be F.log_softmax
# Lưu ý: Một mục tiêu tiêu chuẩn hơn ở đây sẽ là F.log_softmax
) * (T * T)
# 2. Hard Loss (Standard Cross-Entropy)
# 2. Mất mát Cứng (Cross-Entropy Tiêu chuẩn)
hard_loss = F.cross_entropy(student_logits, labels)
# 3. Feature Loss (Latent Layer Distillation)
# 3. Mất mát Đặc trưng (Chưng cất Tầng Tiềm ẩn)
# We use Mean Squared Error (MSE) loss
# Chúng ta sử dụng mất mát Lỗi Trung bình Bình phương (MSE)
feature_loss = F.mse_loss(student_features, teacher_features)
# Combine the losses
# Kết hợp các mất mát
# Logit/Hard loss combo is weighted by (1-alpha) and alpha
# Tổ hợp mất mát Logit/Cứng được cân bằng trọng số bởi (1-alpha) và alpha
# The feature loss is then added, weighted by gamma
# Mất mát đặc trưng sau đó được thêm vào, cân bằng trọng số bởi gamma
combined_loss = (alpha * hard_loss) + ((1 - alpha) * soft_loss) \
+ (gamma * feature_loss)
return combined_loss
- Hàm Mất mát Chưng cất
Đây là logic cốt lõi của thí nghiệm. Hàm này tính toán một giá trị mất mát kết hợp duy nhất từ ba thành phần khác nhau:soft_loss(Mất mát Mềm): Đây là mất mát KD cổ điển. Nó đo lường sự khác biệt (sử dụng Phân kỳ KL) giữa các phân phối xác suất “đã được làm mềm” của học sinh và giáo viên. Chia choT(Nhiệt độ) làm cho các phân phối “mềm hơn”, và nhân với(T * T)để điều chỉnh lại độ lớn của gradient về mức hợp lý.hard_loss(Mất mát Cứng): Đây là mất mát cross-entropy tiêu chuẩn, so sánhlogitscủa học sinh với các nhãn thật. Điều này đảm bảo học sinh vẫn học cách dự đoán câu trả lời đúng.- feature_loss (Mất mát Đặc trưng): Đây là thành phần mới. Nó sử dụng Lỗi Trung bình Bình phương (mse_loss) để buộc các features_adapted (đặc trưng đã điều hợp) của học sinh càng giống về mặt số học với features (đặc trưng) của giáo viên càng tốt.Hàm này sau đó trả về một tổng có trọng số của ba loại mất mát này, sử dụng alpha để cân bằng các mất mát logit cứng/mềm và gamma để kiểm soát sức mạnh của mất mát khớp đặc trưng.
def train_distillation(
student,
teacher,
train_loader,
optimizer,
epoch,
T,
alpha,
gamma
):
"""Training loop for full knowledge distillation (logits + features)."""
"""Vòng lặp huấn luyện cho chưng cất tri thức đầy đủ (logits + đặc trưng)."""
student.train()
teacher.eval() # Teacher is in eval mode
# Giáo viên ở chế độ đánh giá
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# Get student outputs
# Lấy đầu ra của học sinh
student_logits, student_features = student(data)
# Get teacher outputs (with no_grad)
# Lấy đầu ra của giáo viên (với no_grad)
with torch.no_grad():
teacher_logits, teacher_features = teacher(data)
# Calculate the combined distillation loss
# Tính toán mất mát chưng cất kết hợp
loss = distillation_loss(
student_logits, target, teacher_logits,
student_features, teacher_features,
T, alpha, gamma
)
loss.backward()
optimizer.step()
print(f"Train Epoch: {epoch} \tKD Loss: {loss.item():.6f}")
- Vòng lặp Huấn luyện Chưng cấtĐây là hàm huấn luyện sử dụng distillation_loss.
student.train(): Đặt mô hình học sinh vào chế độ huấn luyện (bật dropout, v.v.).teacher.eval(): Quan trọng là, đặt mô hình giáo viên vào chế độ đánh giá. Điều này đóng băng các trọng số của giáo viên (ví dụ: trong batchnorm) và, quan trọng hơn, đảm bảo trọng số của nó không bị cập nhật.- Trong vòng lặp:
- Nó lấy đầu ra từ cả học sinh và giáo viên.
with torch.no_grad()được sử dụng cho lượt truyền của giáo viên để ngăn gradient được tính toán cho giáo viên, tiết kiệm bộ nhớ.- Nó gọi hàm
distillation_lossvới tất cả các đầu vào cần thiết (logits và đặc trưng từ cả hai mô hình, cộng với nhãn và các siêu tham số). loss.backward()tính toán gradient chỉ cho các tham số của mô hình học sinh.- optimizer.step() cập nhật chỉ các trọng số của mô hình học sinh.
# --- 6. Main Execution ---
# --- 6. Thực thi Chính ---
# --- Step A: Train the Teacher ---
# --- Bước A: Huấn luyện Mô hình Giáo viên ---
print("--- 1. Training Teacher Model ---")
teacher_model = TeacherNet().to(device)
optimizer_teacher = optim.SGD(teacher_model.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
for epoch in range(1, EPOCHS_TEACHER + 1):
# Note: We update train_standard to handle the new model output
# Lưu ý: Chúng ta cập nhật train_standard để xử lý đầu ra mới của mô hình
train_standard(teacher_model, train_loader, optimizer_teacher, epoch)
print("\n--- Evaluating Teacher Model ---")
teacher_acc = evaluate(teacher_model, test_loader)
- Thực thi Chính (Bước A: Huấn luyện Giáo viên)
Đây là bước đầu tiên của thí nghiệm.- Một bản sao của
TeacherNetđược tạo và di chuyển đến GPU/CPU (device). - Một trình tối ưu hóa SGD được tạo để cập nhật các tham số của giáo viên.
- Hàm
train_standardđược gọi trongEPOCHS_TEACHER(5) epochs. Điều này huấn luyện mô hình giáo viên một cách bình thường, chỉ sử dụng các nhãn thật. - Cuối cùng, giáo viên đã được huấn luyện được đánh giá trên tập kiểm tra và độ chính xác của nó được lưu trữ trong teacher_acc.
- Một bản sao của
# --- Step B: Train Student with Knowledge Distillation ---
# --- Bước B: Huấn luyện Học sinh bằng Chưng cất Tri thức ---
print("\n--- 2. Training Student with Full Distillation (Logits + Features) ---")
student_model_kd = StudentNet().to(device)
optimizer_student_kd = optim.SGD(student_model_kd.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
for epoch in range(1, EPOCHS_STUDENT + 1):
train_distillation(
student=student_model_kd,
teacher=teacher_model,
train_loader=train_loader,
optimizer=optimizer_student_kd,
epoch=epoch,
T=TEMPERATURE,
alpha=ALPHA,
gamma=GAMMA
)
print("\n--- Evaluating Distilled Student Model ---")
student_kd_acc = evaluate(student_model_kd, test_loader)
- Thực thi Chính (Bước B: Huấn luyện Học sinh được Chưng cất)
Đây là bước thứ hai, nơi diễn ra quá trình chuyển giao tri thức.- Một bản sao của
StudentNetđược tạo (student_model_kd). - Một trình tối ưu hóa SGD được tạo cho các tham số của học sinh.
- Hàm đặc biệt
train_distillationđược gọi trongEPOCHS_STUDENT(10) epochs. Nó truyền vào cảstudent(sẽ được huấn luyện) vàteacher_modelđã được huấn luyện (để cung cấp hướng dẫn). - Mô hình học sinh “được chưng cất” kết quả được đánh giá, và độ chính xác của nó được lưu trữ trong student_kd_acc.
- Một bản sao của
# --- Step C: Train Student from Scratch (for comparison) ---
# --- Bước C: Huấn luyện Học sinh từ đầu (để so sánh) ---
print("\n--- 3. Training Student from Scratch (Baseline) ---")
student_model_scratch = StudentNet().to(device)
optimizer_student_scratch = optim.SGD(student_model_scratch.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
for epoch in range(1, EPOCHS_STUDENT + 1):
train_standard(student_model_scratch, train_loader, optimizer_student_scratch, epoch)
print("\n--- Evaluating 'Scratch' Student Model ---")
student_scratch_acc = evaluate(student_model_scratch, test_loader)
- Thực thi Chính (Bước C: Huấn luyện Học sinh Cơ sở)
Đây là thí nghiệm đối chứng, rất quan trọng để có sự so sánh công bằng.- Một bản sao mới, riêng biệt của
StudentNetđược tạo (student_model_scratch). - Một trình tối ưu hóa mới được tạo cho các tham số của nó.
- Học sinh này được huấn luyện bằng hàm
train_standard—giống như cách giáo viên được huấn luyện. Nó không bao giờ thấy mô hình giáo viên; nó chỉ học từ các nhãn thật. - Mô hình học sinh “từ đầu” này được đánh giá, và độ chính xác của nó được lưu trữ trong student_scratch_acc.
- Một bản sao mới, riêng biệt của
# --- 4. Final Comparison ---
# --- 4. So sánh Cuối cùng ---
print("\n" + "="*30)
print("--- Final Results ---")
print(f"Teacher Model:\t\tParams: {count_parameters(teacher_model):,}\tAccuracy: {teacher_acc:.2f}%")
print(f"Student (Distilled):\tParams: {count_parameters(student_model_kd):,}\tAccuracy: {student_kd_acc:.2f}%")
print(f"Student (Scratch):\tParams: {count_parameters(student_model_scratch):,}\tAccuracy: {student_scratch_acc:.2f}%")
print("="*30)
- Thực thi Chính (Bước 4: So sánh Cuối cùng)
Khối cuối cùng này in ra một bản tóm tắt các kết quả. Nó sử dụng hàm count_parameters để hiển thị kích thước của các mô hình và in ra độ chính xác cuối cùng.Kết quả mong đợi là:
- Giáo viên (Teacher): Số lượng tham số cao, độ chính xác cao.
- Học sinh (Từ đầu – Scratch): Số lượng tham số thấp, độ chính xác thấp hơn.
- Học sinh (Được chưng cất – Distilled): Số lượng tham số thấp (giống như ‘scratch’), nhưng độ chính xác cao hơn học sinh ‘scratch’, chứng tỏ nó đã học thành công “tri thức ẩn” (dark knowledge) từ giáo viên.
Toàn bộ mã:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# --- 1. Settings and Hyperparameters ---
# --- 1. Cài đặt và Siêu tham số ---
# Training settings
# Cài đặt huấn luyện
BATCH_SIZE = 64
EPOCHS_TEACHER = 5
EPOCHS_STUDENT = 10
LEARNING_RATE = 0.01
MOMENTUM = 0.9
# Knowledge Distillation (KD) settings
# Cài đặt Chưng cất Tri thức (KD)
TEMPERATURE = 10 # Temperature for softening probabilities
# Nhiệt độ để làm mềm xác suất
ALPHA = 0.1 # Weight for the "hard" (true label) loss. (1-ALPHA) is for the "soft" (logit) loss.
# Trọng số cho mất mát "cứng" (nhãn thật). (1-ALPHA) là cho mất mát "mềm" (logit).
GAMMA = 1.0 # Weight for the "feature" (latent) loss.
# Trọng số cho mất mát "đặc trưng" (tiềm ẩn).
# Set device
# Thiết lập thiết bị
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# --- 2. Data Loading (MNIST) ---
# --- 2. Tải Dữ liệu (MNIST) ---
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
# --- 3. Model Definitions (Updated) ---
# --- 3. Định nghĩa Mô hình (Đã cập nhật) ---
class TeacherNet(nn.Module):
"""Teacher model now returns final logits AND intermediate features."""
"""Mô hình Giáo viên (Teacher) giờ đây trả về logits cuối cùng VÀ các đặc trưng trung gian."""
def __init__(self):
super(TeacherNet, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(64 * 7 * 7, 256)
self.fc2 = nn.Linear(256, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
# --- Extract intermediate features ---
# --- Trích xuất các đặc trưng trung gian ---
# These are the features we will force the student to mimic
# Đây là những đặc trưng chúng ta sẽ buộc học sinh bắt chước
features = self.pool(F.relu(self.conv2(x))) # Shape: [B, 64, 7, 7]
x_flat = features.view(-1, 64 * 7 * 7) # Flatten
x = F.relu(self.fc1(x_flat))
logits = self.fc2(x) # Output raw logits
return logits, features
class StudentNet(nn.Module):
"""Student model now includes a 'feature adapter' and returns adapted features."""
"""Mô hình Học sinh (Student) giờ đây bao gồm một 'bộ điều hợp đặc trưng' và trả về các đặc trưng đã được điều hợp."""
def __init__(self):
super(StudentNet, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# --- Feature Adapter ---
# --- Bộ điều hợp Đặc trưng ---
# This module's job is to transform the student's features
# (16 channels, 14x14) into the teacher's feature shape (64 channels, 7x7).
# Nhiệm vụ của mô-đun này là biến đổi các đặc trưng của học sinh
# (16 kênh, 14x14) thành hình dạng đặc trưng của giáo viên (64 kênh, 7x7).
self.feature_adapter = nn.Sequential(
nn.Conv2d(16, 64, kernel_size=1), # 1x1 conv to match channels
nn.AdaptiveAvgPool2d((7, 7)) # Avg pool to match spatial dimensions
)
self.fc1 = nn.Linear(16 * 14 * 14, 32) # FC layer still uses the original 14x14 features
self.fc2 = nn.Linear(32, 10)
def forward(self, x):
# --- Student's base features ---
# --- Các đặc trưng cơ sở của Học sinh ---
x_conv = self.pool(F.relu(self.conv1(x))) # Shape: [B, 16, 14, 14]
# --- Adapt features for comparison ---
# --- Điều hợp các đặc trưng để so sánh ---
features_adapted = self.feature_adapter(x_conv) # Shape: [B, 64, 7, 7]
# --- Continue to classification ---
# --- Tiếp tục đến phần phân loại ---
x_flat = x_conv.view(-1, 16 * 14 * 14) # Flatten original features
x = F.relu(self.fc1(x_flat))
logits = self.fc2(x) # Output raw logits
return logits, features_adapted
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
# --- 4. Standard Training and Evaluation (Updated) ---
# --- 4. Huấn luyện và Đánh giá Tiêu chuẩn (Đã cập nhật) ---
def train_standard(model, train_loader, optimizer, epoch):
"""Standard training loop (now ignores the second model output)."""
"""Vòng lặp huấn luyện tiêu chuẩn (bây giờ bỏ qua đầu ra thứ hai của mô hình)."""
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# Models now return (logits, features). We only need logits here.
# Các mô hình giờ trả về (logits, features). Chúng ta chỉ cần logits ở đây.
output, _ = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
print(f"Train Epoch: {epoch} \tLoss: {loss.item():.6f}")
def evaluate(model, test_loader):
"""Standard evaluation loop (now ignores the second model output)."""
"""Vòng lặp đánh giá tiêu chuẩn (bây giờ bỏ qua đầu ra thứ hai của mô hình)."""
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
# Models now return (logits, features). We only need logits here.
# Các mô hình giờ trả về (logits, features). Chúng ta chỉ cần logits ở đây.
output, _ = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'Test set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)')
return accuracy
# --- 5. Knowledge Distillation Loss and Training (Updated) ---
# --- 5. Mất mát Chưng cất Tri thức và Huấn luyện (Đã cập nhật) ---
def distillation_loss(
student_logits,
labels,
teacher_logits,
student_features,
teacher_features,
T,
alpha,
gamma
):
"""
Calculates the *combined* knowledge distillation loss.
Now includes:
1. Hard Loss (Cross-Entropy)
2. Soft Loss (KL Divergence on logits)
3. Feature Loss (MSE on feature maps)
"""
"""
Tính toán mất mát chưng cất tri thức *kết hợp*.
Bây giờ bao gồm:
1. Mất mát Cứng (Cross-Entropy)
2. Mất mát Mềm (Phân kỳ KL trên logits)
3. Mất mát Đặc trưng (MSE trên các bản đồ đặc trưng)
"""
# 1. Soft Loss (Logit Distillation)
# 1. Mất mát Mềm (Chưng cất Logit)
soft_loss = nn.KLDivLoss(reduction='batchmean', log_target=True)(
F.log_softmax(student_logits / T, dim=1),
F.softmax(teacher_logits / T, dim=1)
) * (T * T)
# 2. Hard Loss (Standard Cross-Entropy)
# 2. Mất mát Cứng (Cross-Entropy Tiêu chuẩn)
hard_loss = F.cross_entropy(student_logits, labels)
# 3. Feature Loss (Latent Layer Distillation)
# 3. Mất mát Đặc trưng (Chưng cất Tầng Tiềm ẩn)
# We use Mean Squared Error (MSE) loss
# Chúng ta sử dụng mất mát Lỗi Trung bình Bình phương (MSE)
feature_loss = F.mse_loss(student_features, teacher_features)
# Combine the losses
# Kết hợp các mất mát
# Logit/Hard loss combo is weighted by (1-alpha) and alpha
# Tổ hợp mất mát Logit/Cứng được cân bằng trọng số bởi (1-alpha) và alpha
# The feature loss is then added, weighted by gamma
# Mất mát đặc trưng sau đó được thêm vào, cân bằng trọng số bởi gamma
combined_loss = (alpha * hard_loss) + ((1 - alpha) * soft_loss) \
+ (gamma * feature_loss)
return combined_loss
def train_distillation(
student,
teacher,
train_loader,
optimizer,
epoch,
T,
alpha,
gamma
):
"""Training loop for full knowledge distillation (logits + features)."""
"""Vòng lặp huấn luyện cho chưng cất tri thức đầy đủ (logits + đặc trưng)."""
student.train()
teacher.eval() # Teacher is in eval mode
# Giáo viên ở chế độ đánh giá
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# Get student outputs
# Lấy đầu ra của học sinh
student_logits, student_features = student(data)
# Get teacher outputs (with no_grad)
# Lấy đầu ra của giáo viên (với no_grad)
with torch.no_grad():
teacher_logits, teacher_features = teacher(data)
# Calculate the combined distillation loss
# Tính toán mất mát chưng cất kết hợp
loss = distillation_loss(
student_logits, target, teacher_logits,
student_features, teacher_features,
T, alpha, gamma
)
loss.backward()
optimizer.step()
print(f"Train Epoch: {epoch} \tKD Loss: {loss.item():.6f}")
# --- 6. Main Execution ---
# --- 6. Thực thi Chính ---
# --- Step A: Train the Teacher ---
# --- Bước A: Huấn luyện Mô hình Giáo viên ---
print("--- 1. Training Teacher Model ---")
teacher_model = TeacherNet().to(device)
optimizer_teacher = optim.SGD(teacher_model.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
for epoch in range(1, EPOCHS_TEACHER + 1):
# Note: We update train_standard to handle the new model output
# Lưu ý: Chúng ta cập nhật train_standard để xử lý đầu ra mới của mô hình
train_standard(teacher_model, train_loader, optimizer_teacher, epoch)
print("\n--- Evaluating Teacher Model ---")
teacher_acc = evaluate(teacher_model, test_loader)
# --- Step B: Train Student with Knowledge Distillation ---
# --- Bước B: Huấn luyện Học sinh bằng Chưng cất Tri thức ---
print("\n--- 2. Training Student with Full Distillation (Logits + Features) ---")
student_model_kd = StudentNet().to(device)
optimizer_student_kd = optim.SGD(student_model_kd.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
for epoch in range(1, EPOCHS_STUDENT + 1):
train_distillation(
student=student_model_kd,
teacher=teacher_model,
train_loader=train_loader,
optimizer=optimizer_student_kd,
epoch=epoch,
T=TEMPERATURE,
alpha=ALPHA,
gamma=GAMMA
)
print("\n--- Evaluating Distilled Student Model ---")
student_kd_acc = evaluate(student_model_kd, test_loader)
# --- Step C: Train Student from Scratch (for comparison) ---
# --- Bước C: Huấn luyện Học sinh từ đầu (để so sánh) ---
print("\n--- 3. Training Student from Scratch (Baseline) ---")
student_model_scratch = StudentNet().to(device)
optimizer_student_scratch = optim.SGD(student_model_scratch.parameters(), lr=LEARNING_RATE, momentum=MOMENTUM)
for epoch in range(1, EPOCHS_STUDENT + 1):
train_standard(student_model_scratch, train_loader, optimizer_student_scratch, epoch)
print("\n--- Evaluating 'Scratch' Student Model ---")
student_scratch_acc = evaluate(student_model_scratch, test_loader)
# --- 4. Final Comparison ---
# --- 4. So sánh Cuối cùng ---
print("\n" + "="*30)
print("--- Final Results ---")
print(f"Teacher Model:\t\tParams: {count_parameters(teacher_model):,}\tAccuracy: {teacher_acc:.2f}%")
print(f"Student (Distilled):\tParams: {count_parameters(student_model_kd):,}\tAccuracy: {student_kd_acc:.2f}%")
print(f"Student (Scratch):\tParams: {count_parameters(student_model_scratch):,}\tAccuracy: {student_scratch_acc:.2f}%")
print("="*30)
Theo