



















Bạn tưởng tượng có một bữa tiệc với 2 nhóm khách mời: nhóm “Mèo” và nhóm “Chó”. Nhiệm vụ của bạn là tìm một đường ranh giới (siêu phẳng) để phân chia hai nhóm này thật chuẩn, sao cho không có chú mèo nào chạy sang khu của chó, và ngược lại.
Nhưng mà SVM không chỉ phân chia đơn giản – nó còn muốn đường ranh giới phải thật “rộng rãi”, cách xa cả mèo lẫn chó nhất có thể. Càng xa, càng giảm nguy cơ nhầm lẫn. Đây chính là triết lý tối ưu của SVM: tối đa hóa khoảng cách (margin) giữa ranh giới và những điểm dữ liệu gần nhất.
💡 Những điều cần biết về SVM:
- Véc tơ hỗ trợ là ai?
Những “vị khách” đứng gần đường ranh giới nhất – chính họ quyết định cách SVM đặt đường chia. Họ được gọi là support vectors – như kiểu các “cột mốc” giúp định vị ranh giới. - SVM không thích vòng vo? Có kernel giúp!
Nếu dữ liệu không thể chia tuyến tính (ví dụ: chó và mèo ngồi lộn xộn hình tròn), SVM dùng “phép biến hình” gọi là kernel trick để đưa dữ liệu lên không gian cao hơn, nơi có thể vạch ra một đường chia thẳng thớm.
Một số hàm kernel phổ biến gồm:- Tuyến tính (Linear)
- Đa thức (Polynomial)
- Gaussian RBF (trông như sóng nước)
- Sigmoid (hơi giống mạng nơ-ron)
- Ứng dụng thực tế cực chất:
- Phân loại email spam/không spam
- Nhận diện khuôn mặt
- Dự đoán bệnh lý
- Phân loại văn bản, âm thanh, ảnh…
✅ Ưu điểm:
- Hiệu quả cao với dữ liệu nhiều chiều
- Rất mạnh với bài toán phân loại rõ ràng
- Linh hoạt nhờ kernel, xử lý cả dữ liệu “quái chiêu”
❌ Nhược điểm:
- Chậm nếu dữ liệu siêu lớn
- Cần chọn đúng kernel và tham số phù hợp (khá đau đầu!)
🎉 Tóm lại:
SVM giống như một người bảo vệ khéo léo – biết cách đứng ở giữa, giữ khoảng cách đều với cả hai phe, và sẵn sàng “hô biến” không gian để chia ranh giới nếu cần. Vừa mạnh mẽ, vừa duyên dáng!
chi tiết hơn:
Giới thiệu về Máy Véc Tơ Hỗ Trợ (SVM)
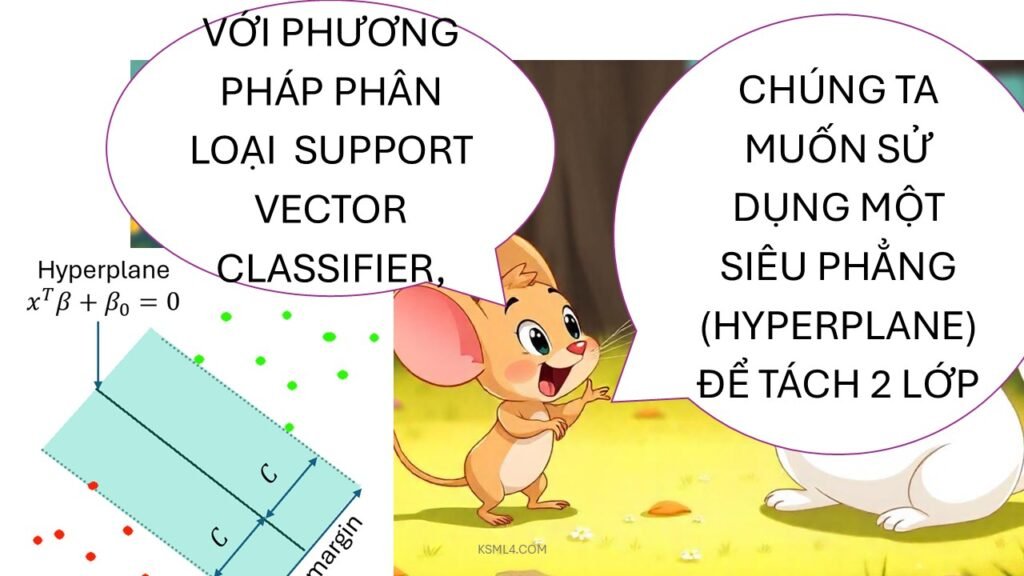
Máy Véc Tơ Hỗ Trợ (SVM – Support Vector Machine) là một trong những thuật toán học máy được sử dụng rộng rãi trong lĩnh vực phân loại và hồi quy. Định nghĩa đơn giản, SVM là một phương pháp mà mục tiêu chính của nó là tạo ra một siêu phẳng (hyperplane) phân chia các lớp dữ liệu khác nhau trong không gian nhiều chiều. Bằng cách tìm kiếm siêu phẳng tối ưu, SVM có thể phân loại dữ liệu hiệu quả và chính xác.
Nguyên lý hoạt động của SVM dựa trên việc tối đa hóa khoảng cách giữa các điểm dữ liệu của các lớp khác nhau, với mong muốn đạt được một siêu phẳng phân chia tốt nhất. Các điểm gần với siêu phẳng, được gọi là các vector hỗ trợ, là rất quan trọng trong quá trình tối ưu này. Chỉ cần một số lượng điểm dữ liệu nhất định nằm gần siêu phẳng cũng đủ để xác định vị trí của nó, điều này giúp SVM hoạt động hiệu quả ngay cả trong những tập dữ liệu lớn.
SVM không chỉ dừng lại ở việc phân loại tuyến tính; nó còn có khả năng xử lý các bài toán phân loại phi tuyến thông qua việc sử dụng các hạt nhân (kernel functions). Những hạt nhân này cho phép SVM chuyển đổi dữ liệu vào không gian có chiều cao hơn, nơi mà các lớp có thể được phân tách dễ dàng hơn. Nhờ vào đặc điểm này, SVM đã trở thành một trong những thuật toán được ưa chuộng trong nhiều lĩnh vực khác nhau, từ nhận dạng hình ảnh đến phân tích văn bản.
Với khả năng cung cấp độ chính xác cao và tính linh hoạt trong việc xử lý dữ liệu đa dạng, SVM đang ngày càng khẳng định vai trò quan trọng trong lĩnh vực học máy hiện đại. Sự phát triển của máy học đã giúp SVM không ngừng mở rộng và cải thiện, mang lại những ứng dụng thực tiễn đầy hứa hẹn trong tương lai.
Cấu trúc và Nguyên lý hoạt động của SVM
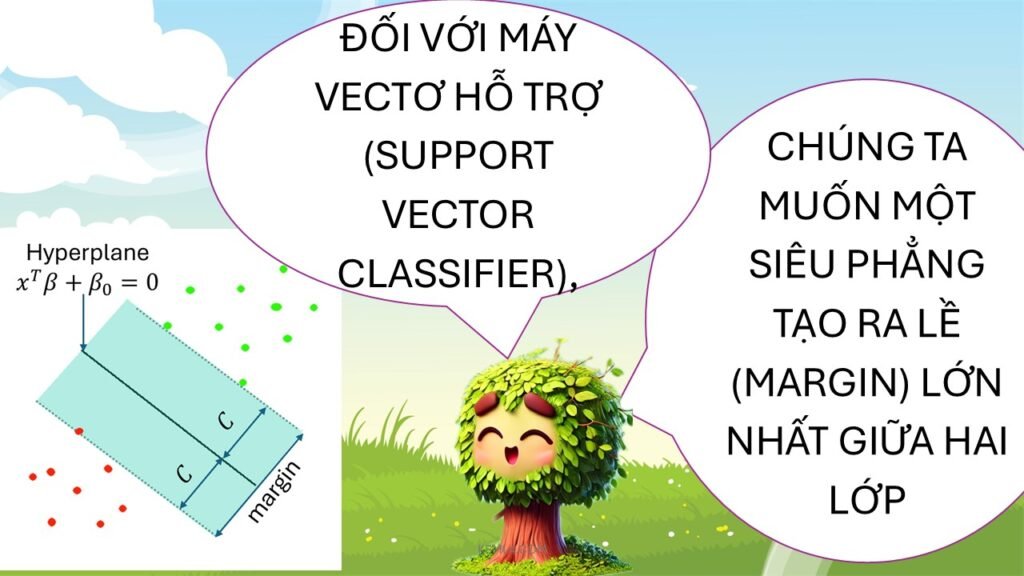
Máy Véc Tơ Hỗ Trợ (SVM) là một trong những thuật toán học máy mạnh mẽ nhất hiện có, chủ yếu được sử dụng trong các bài toán phân loại. Cấu trúc của SVM xoay quanh khái niệm hyperplane, một không gian có thể chia các điểm dữ liệu thành hai lớp khác nhau. Véc tơ hỗ trợ là những điểm dữ liệu mà gần hyperplane nhất, và chúng có vai trò rất quan trọng trong việc xác định vị trí của hyperplane. Khi đưa ra quyết định phân loại, SVM tìm kiếm hyperplane tối ưu, tức là hyperplane mà tạo ra khoảng cách lớn nhất giữa các lớp dữ liệu. Khoảng cách này được gọi là margin.
Khi dữ liệu được trình bày dưới dạng vector trong không gian đa chiều, SVM cố gắng xác định hyperplane sao cho margin giữa các lớp là tối ưu. Quá trình này bao gồm việc tối thiểu hóa một hàm mục tiêu trong đó margin được tối ưu hóa dựa trên các phối hợp của véc tơ hỗ trợ. Chính vì thế, SVM có khả năng phát hiện và xây dựng bề mặt quyết định cho các lớp khác nhau của dữ liệu với độ chính xác cao.
Các thuật toán SVM có thể mở rộng để xử lý dữ liệu không tuyến tính bằng cách sử dụng các kỹ thuật biến đổi không gian, như kernel trick, cho phép các cây hyperplane trở nên phi tuyến tính trong không gian đầu vào. Quá trình này hỗ trợ SVM trở thành một công cụ mạnh mẽ cho nhiều loại bài toán phân loại khác nhau. Đặc biệt, việc sử dụng hàm kernel giúp tăng cường khả năng phân loại cho những tập dữ liệu phức tạp, từ đó tạo ra những kết quả tốt hơn trong việc triển khai thực tế.
Ứng dụng của Máy Véc Tơ Hỗ Trợ trong thực tiễn
Máy Véc Tơ Hỗ Trợ (SVM) là một trong những phương pháp học máy tiên tiến được áp dụng rộng rãi trong nhiều lĩnh vực. Một trong những ứng dụng nổi bật của SVM là trong nhận dạng hình ảnh. Hệ thống nhận dạng hình ảnh sử dụng SVM để phân loại các đối tượng trong ảnh, chẳng hạn như nhận diện khuôn mặt hay phân loại hình ảnh động vật, từ đó hỗ trợ nhiều ứng dụng trong công nghệ thông tin và an ninh mạng.
Trong lĩnh vực phân loại văn bản, SVM được sử dụng để phân loại email thành thư rác hoặc không phải thư rác. Các mô hình SVM nhận diện các đặc điểm của văn bản để xác định nội dung phù hợp, giúp người dùng tiết kiệm thời gian và làm choInbox sáng sủa hơn. Hơn nữa, SVM còn hữu ích trong việc phân tích cảm xúc, giúp các doanh nghiệp đánh giá phản hồi của khách hàng từ các bài đánh giá hoặc bài viết trên mạng xã hội, từ đó tạo ra chiến lược nội dung hiệu quả hơn.
Trong lĩnh vực tài chính, SVM được sử dụng để dự đoán xu hướng thị trường và phân loại các sản phẩm tài chính. Một số nhà đầu tư sử dụng SVM để phân tích biến động giá cổ phiếu hoặc dự đoán sự tăng giảm của thị trường trong tương lai. Công nghệ này cho phép đưa ra quyết định đầu tư chính xác hơn, giảm thiểu rủi ro tổn thất. Tóm lại, sự linh hoạt và khả năng xử lý các bài toán phức tạp của SVM làm cho nó trở thành một công cụ mạnh mẽ ở nhiều lĩnh vực, từ nhận diện đến quyết định tài chính.
So sánh SVM với các thuật toán học máy khác
Máy véc tơ hỗ trợ (SVM) là một trong những thuật toán học máy được ưa chuộng cho nhiệm vụ phân loại và hồi quy. Để hiểu rõ hơn về vị thế của SVM trong lĩnh vực học máy, cần so sánh nó với một số thuật toán phổ biến khác như cây quyết định, hồi quy logistic và mạng nơ-ron.
Cây quyết định là một trong những phương pháp đơn giản và dễ hiểu, cung cấp kết quả trực quan thông qua các quyết định dạng phân nhánh. Tuy nhiên, chúng dễ dàng bị ảnh hưởng bởi các biến bất thường do cách mà cây quyết định phân chia không gian. Ngược lại, SVM có khả năng tìm ra ranh giới phân chia tối ưu giữa các lớp dữ liệu, giúp cải thiện độ chính xác trong nhiều trường hợp phức tạp.
Hồi quy logistic là một lựa chọn phổ biến cho các bài toán phân loại nhị phân. Mặc dù hiệu quả đối với các dữ liệu tuyến tính, nó không hoạt động tốt với các dữ liệu phi tuyến. SVM vượt trội hơn ở điểm này, nhờ vào khả năng sử dụng các nhân (kernel) khác nhau, cho phép xử lý các mối quan hệ phi tuyến giữa các đặc trưng.
Mạng nơ-ron, nhất là trong bối cảnh học sâu, đã tạo ra những bước đột phá lớn trong nhiều lĩnh vực như nhận diện hình ảnh và xử lý ngôn ngữ tự nhiên. Tuy nhiên, mạng nơ-ron cần nhiều dữ liệu để đạt hiệu suất tốt và có thể bị quá khớp (overfitting) với tập huấn luyện. Đối lại, SVM có thể đạt được hiệu suất tốt hơn với số lượng dữ liệu nhỏ hơn nhờ vào quy trình tối ưu hóa và các quy tắc điều chỉnh mà nó áp dụng.
Nhìn chung, mỗi thuật toán học máy đều có những ưu và nhược điểm riêng. SVM nổi bật với khả năng xử lý tốt các vấn đề phi tuyến và độ chính xác cao, nhưng cũng cần cân nhắc để lựa chọn phương pháp học máy phù hợp nhất cho từng bài toán cụ thể.