Phân loại phân cấp (Hierarchical classification) là một phương pháp gán các mục vào một danh mục, mà danh mục đó là một phần của một hệ thống phân cấp lớn hơn, có cấu trúc. Không giống như phương pháp phân loại “phẳng” (flat classification) truyền thống, nơi các danh mục độc lập với nhau, phân loại phân cấp xem xét các mối quan hệ giữa các danh mục, sắp xếp chúng theo cấu trúc cha-con. Cách tiếp cận này đặc biệt hữu ích khi xử lý các lĩnh vực phức tạp mà việc phân loại đơn giản ở một cấp độ là không đủ.
Một ví dụ kinh điển là phân loại sinh học của các sinh vật sống, trong đó các loài được nhóm vào chi, sau đó là họ, bộ, lớp, ngành và cuối cùng là giới. Mỗi cấp độ đại diện cho một danh mục rộng hơn và bao quát hơn. Ví dụ, một con sư tử được xếp vào chi Panthera, thuộc họ Felidae (họ Mèo), và họ này lại thuộc bộ Carnivora (bộ Ăn thịt), và cứ thế tiếp tục lên các cấp cao hơn trong hệ thống phân cấp.
Trong lĩnh vực học máy (machine learning), phân loại phân cấp được sử dụng để giải quyết các bài toán phân loại phức tạp bằng cách chia chúng thành một chuỗi các quyết định đơn giản hơn. Thay vì một mô hình duy nhất dự đoán từ một số lượng lớn các lớp, người ta có thể sử dụng một hệ thống phân cấp gồm nhiều bộ phân loại. Điều này có thể cải thiện độ chính xác và cung cấp kết quả dễ diễn giải hơn. Ví dụ, trong phân loại tài liệu, một tài liệu trước tiên có thể được phân loại là “thể thao” hoặc “chính trị”, và sau đó một bộ phân loại tiếp theo có thể phân loại sâu hơn một tài liệu “thể thao” thành “bóng rổ”, “bóng đá” hoặc “quần vợt”.
Các cách tiếp cận chính trong Học máy:
Có hai chiến lược chính để triển khai phân loại phân cấp trong học máy:
- Bộ phân loại cục bộ (Local Classifiers): Cách tiếp cận này liên quan đến việc huấn luyện một bộ phân loại riêng biệt cho mỗi nút hoặc mỗi cấp trong hệ thống phân cấp.
- Bộ phân loại cục bộ cho mỗi nút (Local Classifier per Node): Một bộ phân loại nhị phân được huấn luyện cho mỗi lớp để quyết định xem một mẫu có thuộc về lớp đó hay không.
- Bộ phân loại cục bộ cho mỗi nút cha (Local Classifier per Parent Node): Đối với mỗi nút cha, một bộ phân loại đa lớp được huấn luyện để phân biệt giữa các nút con trực tiếp của nó.
- Bộ phân loại cục bộ cho mỗi cấp (Local Classifier per Level): Một bộ phân loại đa lớp duy nhất được huấn luyện cho mỗi cấp của hệ thống phân cấp.
- Bộ phân loại toàn cục (Global Classifier hoặc Big-Bang Approach): Phương pháp này bao gồm việc huấn luyện một mô hình duy nhất, phức tạp hơn, xem xét toàn bộ hệ thống phân cấp lớp đồng thời. Mô hình này được thiết kế để dự đoán lớp cụ thể nhất trong hệ thống phân cấp, và các lớp cha được gán một cách ngầm định.
Ưu điểm và Nhược điểm:
| Ưu điểm | Nhược điểm |
| Cải thiện độ chính xác: Bằng cách chia nhỏ một vấn đề phức tạp thành các bài toán con nhỏ hơn, dễ quản lý hơn, phân loại phân cấp thường có thể dẫn đến các dự đoán chính xác hơn. | Lan truyền lỗi (Error Propagation): Trong cách tiếp cận bộ phân loại cục bộ, một lỗi ở cấp cao hơn của hệ thống phân cấp có thể lan truyền xuống các cấp thấp hơn, dẫn đến kết quả phân loại cuối cùng không chính xác. |
| Khả năng diễn giải: Cấu trúc phân cấp của đầu ra có thể cung cấp nhiều thông tin chi tiết hơn về quyết định phân loại. | Độ phức tạp: Việc triển khai và huấn luyện các mô hình phân cấp có thể phức tạp hơn so với phân loại phẳng truyền thống. |
| Khả năng mở rộng: Nó có thể hiệu quả hơn đối với các bài toán có số lượng danh mục rất lớn. | Dữ liệu thưa thớt (Data Sparsity): Một số lớp cụ thể hơn ở cấp thấp hơn có thể có rất ít mẫu huấn luyện, gây khó khăn cho việc huấn luyện các bộ phân loại chính xác. |
Về cơ bản, phân loại phân cấp cung cấp một khuôn khổ mạnh mẽ để tổ chức và phân loại thông tin một cách có cấu trúc và ý nghĩa, với các ứng dụng trải dài từ khoa học tự nhiên đến các tác vụ học máy tiên tiến.
Ví dụ trong Hệ thống Gợi ý Game
Các hệ thống gợi ý truyền thống có thể sử dụng một cấu trúc thể loại “phẳng”. Một trò chơi được gán các thẻ như “Hành động”, “Nhập vai”, “Chiến thuật”, v.v. Nếu một người dùng chơi nhiều game “Hành động”, hệ thống sẽ gợi ý thêm các game “Hành động” khác.
Cách làm này có hạn chế vì “Hành động” là một danh mục vô cùng rộng lớn. Một người chơi yêu thích các game bắn súng cạnh tranh, nhịp độ nhanh như Valorant (game Bắn súng Chiến thuật FPS) có thể sẽ không thích một game hành động góc nhìn thứ ba, có cốt truyện như The Last of Us (game Hành động-Phiêu lưu), mặc dù cả hai đều thuộc danh mục “Hành động”.
Xây dựng một Hệ thống Phân cấp Thể loại Game
Phân loại phân cấp giải quyết vấn đề này bằng cách sắp xếp các thể loại game thành một cấu trúc dạng cây, từ rộng đến rất cụ thể. Điều này cho phép hệ thống hiểu được sở thích của người dùng ở mức độ chi tiết hơn nhiều.
Dưới đây là một ví dụ đơn giản về hệ thống phân cấp thể loại game:
└── Tất cả Game
├── Hành động (Action)
│ ├── Bắn súng (Shooter)
│ │ ├── Bắn súng góc nhìn thứ nhất (FPS)
│ │ │ ├── Bắn súng chiến thuật (Tactical Shooter) (ví dụ: Valorant, CS:GO)
│ │ │ └── Bắn súng loot đồ (Looter Shooter) (ví dụ: Borderlands, Destiny 2)
│ │ └── Bắn súng góc nhìn thứ ba (TPS) (ví dụ: Gears of War)
│ ├── Hành động-Phiêu lưu (Action-Adventure) (ví dụ: The Last of Us, Tomb Raider)
│ └── Chặt chém / Đối kháng (Hack and Slash / Beat 'em up) (ví dụ: Devil May Cry)
│
├── Nhập vai (Role-Playing Game - RPG)
│ ├── Nhập vai hành động (ARPG) (ví dụ: The Witcher 3, Elden Ring)
│ ├── Nhập vai Nhật Bản (JRPG)
│ │ ├── Theo lượt (Turn-Based) (ví dụ: Persona 5)
│ │ └── Dựa trên hành động (Action-Based) (ví dụ: Final Fantasy XVI)
│ └── Nhập vai chiến thuật (SRPG) (ví dụ: Fire Emblem)
│
└── Chiến thuật (Strategy)
├── Chiến thuật thời gian thực (RTS) (ví dụ: StarCraft II)
└── Chiến thuật theo lượt (TBS) (ví dụ: Civilization VI)
Phân loại Phân cấp Hỗ trợ việc Gợi ý Game như thế nào
Một mô hình học máy (machine learning) sử dụng hệ thống phân cấp này để vừa phân loại game, vừa xây dựng hồ sơ người dùng.
1. Tạo Hồ sơ Người dùng Tinh tế
Thay vì chỉ biết người dùng thích “RPG”, hệ thống có thể tìm hiểu sở thích cụ thể của họ sâu hơn trong hệ thống phân cấp.
- Người dùng A chơi The Witcher 3, Elden Ring, và Diablo IV. Hệ thống xác định một sở thích mạnh mẽ đối với thể loại phụ Nhập vai hành động (ARPG). Nó sẽ không gợi ý một game JRPG theo lượt như Persona 5, mặc dù đó cũng là một game RPG.
- Người dùng B chơi Valorant và Counter-Strike 2. Hệ thống xác định họ là một fan của thể loại Bắn súng Chiến thuật. Gợi ý tiếp theo có khả năng cao là Rainbow Six Siege (một game Bắn súng Chiến thuật khác) thay vì một game Bắn súng loot đồ như Borderlands.
Hệ thống xây dựng hồ sơ người dùng không phải là một danh sách thể loại phẳng, mà là một cây có trọng số, với các sở thích mạnh hơn được chỉ định tại các nút cụ thể trong hệ thống phân cấp.
2. Giải quyết Vấn đề “Khởi đầu Nguội” (Cold Start) cho Game Mới
Khi một game mới được phát hành, nó không có lượt đánh giá hay lịch sử chơi của người dùng. Đây là vấn đề “khởi đầu nguội”. Với hệ thống phân cấp, game mới có thể được phân loại ngay lập tức.
Ví dụ, một game indie mới, “Cosmic Raiders,” được phân loại là Bắn súng loot đồ. Ngay cả khi không có dữ liệu người chơi, hệ thống có thể bắt đầu gợi ý nó cho những người dùng có sở thích đã biết đối với thể loại phụ cụ thể này (như người chơi Destiny 2 hoặc Borderlands). Nó thậm chí có thể gợi ý game này cho những người chơi thích danh mục cha là Bắn súng góc nhìn thứ nhất để thử nghiệm.
3. Cho phép Khám phá Thông minh hơn và Tình cờ Tìm thấy Game Hay
Phân loại phân cấp cho phép hệ thống đưa ra các gợi ý “lân cận”. Nếu người dùng đã chơi hết tất cả các game trong một thể loại phụ rất cụ thể, hệ thống có thể di chuyển lên một cấp trong hệ thống phân cấp và gợi ý một game từ một danh mục “anh em”.
- Một người chơi yêu thích JRPG theo lượt có thể sẵn sàng thử một game Nhập vai chiến thuật (SRPG) như Fire Emblem, vì cả hai đều có yếu tố chiến thuật, theo lượt.
- Một fan của thể loại Kinh dị sinh tồn (một thể loại phụ của Hành động-Phiêu lưu) có thể được gợi ý một game Kinh dị tâm lý.
Điều này giúp người dùng khám phá các loại game mới mà họ có khả năng sẽ thích, ngăn chặn “bong bóng gợi ý” nơi họ chỉ thấy đi thấy lại những thứ giống hệt nhau.
4. Cải thiện Độ chính xác của Gợi ý
Bằng cách chia nhỏ nhiệm vụ phân loại, hệ thống có thể trở nên chính xác hơn. Một mô hình được huấn luyện để phân biệt giữa “Bắn súng Chiến thuật” và “Bắn súng loot đồ” (một nhiệm vụ chi tiết) có thể hoạt động tốt hơn nhiều so với một mô hình lớn duy nhất cố gắng dự đoán một trong hàng nghìn thẻ loại phẳng có thể có. Đây là nguyên tắc “chia để trị”. Một bộ phân loại cục bộ tại mỗi nút chỉ cần giải quyết một vấn đề đơn giản, dẫn đến một hệ thống tổng thể mạnh mẽ hơn.
Tóm lại, việc áp dụng phân loại phân cấp vào gợi ý game biến một hệ thống chung chung thành một công cụ khám phá thông minh và được cá nhân hóa cao. Nó hiểu rằng sở thích của một game thủ rất phức tạp và đa tầng, dẫn đến những đề xuất thỏa mãn và phù hợp hơn, giúp người chơi luôn gắn bó.
Ví dụ trong Python
Trong ví dụ này, ta sẽ xây dựng và đánh giá một mô hình phân loại văn bản có cấu trúc phân cấp (hierarchical text classification). Mục tiêu là phân loại một tài liệu (trong trường hợp này là tóm tắt một bài báo nghiên cứu) không chỉ vào một danh mục duy nhất, mà vào một đường dẫn danh mục, ví dụ như Khoa học máy tính -> Trí tuệ nhân tạo. Nó sử dụng thư viện hiclass, được thiết kế đặc biệt cho loại bài toán này.
1. Cài đặt và Tải Dữ liệu ⚙️
Khối lệnh đầu tiên xử lý việc cài đặt các thư viện cần thiết và tải tập dữ liệu.
Python
#pip install pandas scikit-learn hiclass
import numpy as np
from hiclass.datasets import load_hierarchical_text_classification
# Tải dữ liệu với tỷ lệ phân chia 70/30 cho tập huấn luyện/kiểm tra
# Hàm này xử lý việc tải về, phân tích cú pháp và chia tách dữ liệu.
X_train_text, X_test_text, y_train, y_test = load_hierarchical_text_classification(
test_size=0.3,
random_state=42
)
print("--- Tải Dữ liệu Thành công ---")
print(f"Số lượng mẫu huấn luyện: {X_train_text.shape[0]}")
print(f"Số lượng mẫu kiểm tra: {X_test_text.shape[0]}")
print(f"Kích thước của nhãn huấn luyện: {y_train.shape}")
print("\nVí dụ về một nhãn đã được định dạng trước (cho 'cs.AI'):")
print(y_train[0])pip install ...: Lệnh này cài đặt ba thư viện Python cần thiết:pandas: Dùng để xử lý dữ liệu (mặc dù không được sử dụng trực tiếp trong script này,hiclassdùng nó ở bên trong).scikit-learn: Một thư viện học máy cơ bản trong Python. Chúng ta dùng nó cho bộ vector hóa văn bản, bộ phân loại cơ sở và pipeline.hiclass: Một thư viện chuyên dụng cho phân loại phân cấp, hoạt động trơn tru với scikit-learn.
load_hierarchical_text_classification(...): Đây là một hàm tiện ích từhiclass. Nó tự động tải về một tập dữ liệu các bản tóm tắt bài báo nghiên cứu từ arXiv, nơi mỗi bài báo được phân loại theo một hệ thống phân cấp (ví dụ:cs->AI).X_train_text,X_test_text: Chứa nội dung văn bản thô của các bản tóm tắt để huấn luyện và kiểm tra.y_train,y_test: Chứa các nhãn phân cấp tương ứng. Mỗi nhãn là một mảng chuỗi ký tự đại diện cho đường dẫn. Ví dụ,['cs', 'AI', '']đại diện cho danh mục “Trí tuệ nhân tạo” (Artificial Intelligence) trong “Khoa học máy tính” (Computer Science). Chuỗi rỗng''được dùng để đệm (padding) nhằm đảm bảo tất cả các mảng nhãn có cùng độ dài.test_size=0.3: Phân chia dữ liệu sao cho 30% được dành riêng để kiểm tra hiệu suất của mô hình, và 70% được dùng để huấn luyện.random_state=42: Đảm bảo rằng dữ liệu được phân chia theo cùng một cách mỗi khi bạn chạy mã, giúp kết quả của bạn có thể tái tạo được.
Kết quả
--- Tải Dữ liệu Thành công ---
Số lượng mẫu huấn luyện: 28000
Số lượng mẫu kiểm tra: 12000
Kích thước của nhãn huấn luyện: (28000, 3)
Ví dụ về một nhãn đã được định dạng trước (cho 'cs.AI'):
['health personal care' 'nutrition wellness' 'vitamins supplements']2. Xây dựng Quy trình Học máy (Pipeline) 🏗️
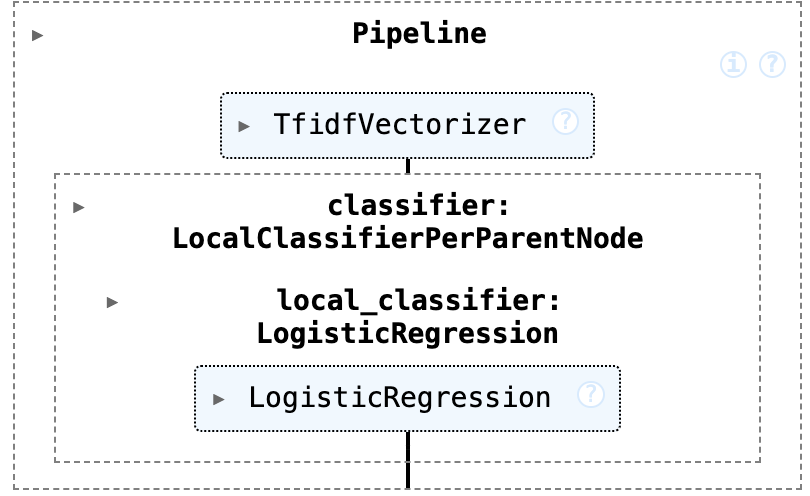
Pipeline là một công cụ mạnh mẽ từ scikit-learn giúp xâu chuỗi nhiều bước lại với nhau. Điều này đảm bảo rằng các hoạt động giống nhau (như xử lý văn bản và phân loại) được áp dụng một cách nhất quán cho cả dữ liệu huấn luyện và kiểm tra. Pipeline của chúng ta có hai giai đoạn chính:
- Vectorizer (Bộ vector hóa): Chuyển đổi văn bản thô thành dữ liệu số.
- Classifier (Bộ phân loại): Học cách dự đoán đường dẫn danh mục từ dữ liệu số.
Python
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from hiclass import LocalClassifierPerParentNode
# 1. Định nghĩa bộ phân loại cơ sở cho mỗi nút
base_classifier = LogisticRegression(solver='liblinear', random_state=42)
# 2. Tạo bộ phân loại phân cấp
hierarchical_classifier = LocalClassifierPerParentNode(
local_classifier=base_classifier,
n_jobs=-1
)
# 3. Xây dựng pipeline hoàn chỉnh
pipeline = Pipeline([
('vectorizer', TfidfVectorizer(
stop_words='english',
max_features=10000,
ngram_range=(1, 2)
)),
('classifier', hierarchical_classifier)
])
TfidfVectorizer: Đây là bước đầu tiên. Nó chuyển đổi các bản tóm tắt văn bản thành một ma trận các đặc trưng TF-IDF.- TF-IDF là viết tắt của Term Frequency-Inverse Document Frequency (Tần suất Thuật ngữ – Tần suất Tài liệu Nghịch đảo). Đây là một chỉ số thống kê phản ánh mức độ quan trọng của một từ đối với một tài liệu trong một bộ sưu tập. Nó gán trọng số cao hơn cho những từ xuất hiện thường xuyên trong một tài liệu nhưng lại hiếm khi xuất hiện trong tất cả các tài liệu khác.
stop_words='english': Loại bỏ các từ tiếng Anh phổ biến như “the”, “a”, và “in”, những từ không mang nhiều ý nghĩa cho việc phân loại.max_features=10000: Chỉ xem xét 10.000 từ xuất hiện thường xuyên nhất để giữ cho mô hình có thể quản lý được.ngram_range=(1, 2): Xem xét cả các từ đơn (như “machine”) và các cặp từ liền kề (như “machine learning”). Điều này giúp nắm bắt ngữ cảnh tốt hơn.
LocalClassifierPerParentNode(LCPN): Đây là trái tim của mô hình phân cấp của chúng ta từ thư việnhiclass.- Chiến lược của nó là huấn luyện một bộ phân loại chuẩn riêng biệt cho mỗi danh mục “cha” trong hệ thống phân cấp. Ví dụ, nó huấn luyện một bộ phân loại ở cấp gốc để quyết định giữa
cs,math,physics, v.v. Sau đó, nếu nó dự đoán làcs, nó sẽ sử dụng một bộ phân loại khác được huấn luyện đặc biệt để phân biệt giữa các “con” củacs(nhưAI,LG,CV). local_classifier=base_classifier: Chúng ta yêu cầu LCPN sử dụng mô hìnhLogisticRegression(Hồi quy Logistic) cho mỗi điểm quyết định này.LogisticRegressionlà một mô hình cơ sở đơn giản, nhanh và hiệu quả cho việc phân loại văn bản.n_jobs=-1: Đây là một mẹo hiệu suất, yêu cầu mô hình sử dụng tất cả các nhân CPU có sẵn để tăng tốc quá trình huấn luyện.
- Chiến lược của nó là huấn luyện một bộ phân loại chuẩn riêng biệt cho mỗi danh mục “cha” trong hệ thống phân cấp. Ví dụ, nó huấn luyện một bộ phân loại ở cấp gốc để quyết định giữa
Kết quả:
3. Huấn luyện Mô hình 🧠
Đây là bước trông có vẻ đơn giản nhất nhưng lại tốn nhiều tài nguyên tính toán nhất.
Python
pipeline.fit(X_train_text, y_train)
pipeline.fit(...): Lệnh duy nhất này thực thi toàn bộ quá trình huấn luyện.TfidfVectorizertrước tiên học từ vựng từX_train_textvà biến đổi văn bản thành một ma trận số.LocalClassifierPerParentNodesau đó lấy ma trận này và các nhãn phân cấpy_trainđể huấn luyện tất cả các mô hìnhLogisticRegressionbên trong nó.
4. Đưa ra Dự đoán 🔮
Bây giờ mô hình đã được huấn luyện, chúng ta có thể sử dụng nó để dự đoán danh mục cho một bản tóm tắt mới, chưa từng thấy từ tập kiểm tra của chúng ta.
Python
from hiclass.metrics import f1
# Chọn một mẫu tóm tắt từ tập kiểm tra
sample_idx = 42
sample_abstract = [X_test_text[sample_idx]]
true_path = y_test[sample_idx]
# Dự đoán hệ thống phân cấp cho mẫu tóm tắt
predicted_path = pipeline.predict(sample_abstract)[0]
# Dọn dẹp các chuỗi rỗng để hiển thị gọn gàng hơn
true_path_clean = list(filter(None, true_path))
predicted_path_clean = list(filter(None, predicted_path))
print("\n--- Prediction Example ---")
# ... (các lệnh in)
pipeline.predict(sample_abstract): Chúng ta đưa một mẫu tóm tắt vào pipeline đã được huấn luyện. Lưu ý rằng đầu vào phải là một đối tượng có thể lặp (như list), đó là lý do tại sao[X_test_text[sample_idx]]được sử dụng.- Pipeline tự động áp dụng các bước tương tự: nó vector hóa văn bản bằng cách sử dụng từ vựng đã học và sau đó sử dụng bộ phân loại phân cấp đã huấn luyện để dự đoán đường dẫn danh mục.
- Hàm
filterlà một mẹo Python hay để loại bỏ các chuỗi đệm''khỏi mảng nhãn, giúp kết quả in ra trông gọn gàng hơn.
5. Đánh giá Hiệu suất Mô hình 📊
Cuối cùng, chúng ta đánh giá hiệu suất của mô hình không chỉ trên một ví dụ, mà trên toàn bộ tập kiểm tra để có một thước đo đáng tin cậy về mức độ hoạt động của nó.
Python
# Đánh giá hiệu suất của mô hình trên toàn bộ tập kiểm tra
y_pred = pipeline.predict(X_test_text)
h_f1_score = f1(y_test, y_pred)
print(f"\nOverall Hierarchical F1-Score on Test Set: {h_f1_score:.4f}")
pipeline.predict(X_test_text): Chúng ta nhận dự đoán cho tất cả các bản tóm tắt trong tập kiểm tra.f1(y_test, y_pred): Chúng ta sử dụng chỉ số đo lườngf1từhiclass. Một điểm F1-score tiêu chuẩn là sự cân bằng giữaprecision(độ chính xác) vàrecall(độ bao phủ), nhưng điểm F1 phân cấp (hierarchical F1-score) này được thiết kế đặc biệt để đo lường hiệu suất trong một cấu trúc phân cấp. Nó thưởng điểm cho các dự đoán đúng một phần (ví dụ: đoán đúng danh mục cấp cao nhất nhưng sai danh mục con) và phạt các dự đoán hoàn toàn sai.- Điểm số cuối cùng cung cấp cho bạn một con số duy nhất tóm tắt mức độ chính xác của các dự đoán phân cấp của mô hình trên toàn bộ tập dữ liệu kiểm tra.
Kết quả
--- Ví dụ Dự đoán ---
Tóm tắt:
'Crown Crafts The Original NoJo BabySling by Dr. Sears in Black Chambray...'
=========================
✅ Đường dẫn Danh mục Đúng: ['baby products', 'gear', 'backpacks carriers']
🤖 Đường dẫn Danh mục Dự đoán: [np.str_('baby products'), np.str_('gear'), np.str_('backpacks carriers')]
Đang đánh giá trên toàn bộ tập kiểm tra...
Tổng điểm F1 Phân cấp trên Tập kiểm tra: 0.8207Toàn bộ code
# Cài đặt các thư viện cần thiết
#pip install pandas scikit-learn hiclass
import numpy as np
from hiclass.datasets import load_hierarchical_text_classification
# Tải dữ liệu với tỷ lệ phân chia 70/30 cho tập huấn luyện/kiểm tra
# Hàm này xử lý việc tải về, phân tích cú pháp và chia tách dữ liệu.
X_train_text, X_test_text, y_train, y_test = load_hierarchical_text_classification(
test_size=0.3,
random_state=42
)
print("--- Tải Dữ liệu Thành công ---")
print(f"Số lượng mẫu huấn luyện: {X_train_text.shape[0]}")
print(f"Số lượng mẫu kiểm tra: {X_test_text.shape[0]}")
print(f"Kích thước của nhãn huấn luyện: {y_train.shape}")
print("\nVí dụ về một nhãn đã được định dạng trước (cho 'cs.AI'):")
print(y_train[0])
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from hiclass import LocalClassifierPerParentNode
# 1. Định nghĩa bộ phân loại cơ sở cho mỗi nút trong hệ thống phân cấp
base_classifier = LogisticRegression(solver='liblinear', random_state=42)
# 2. Tạo bộ phân loại phân cấp
# Phần mã này không thay đổi
hierarchical_classifier = LocalClassifierPerParentNode(
local_classifier=base_classifier,
n_jobs=-1
)
# 3. Xây dựng pipeline hoàn chỉnh
pipeline = Pipeline([
('vectorizer', TfidfVectorizer(
stop_words='english',
max_features=10000,
ngram_range=(1, 2)
)),
('classifier', hierarchical_classifier)
])
pipeline.fit(X_train_text, y_train)
from hiclass.metrics import f1
# Chọn một mẫu tóm tắt từ tập kiểm tra để xem xét
sample_idx = 42
# Chọn chuỗi tại chỉ số và gói nó vào một danh sách cho pipeline
sample_abstract = [X_test_text[sample_idx]]
true_path = y_test[sample_idx]
# Dự đoán hệ thống phân cấp cho mẫu tóm tắt
predicted_path = pipeline.predict(sample_abstract)[0]
# Dọn dẹp các chuỗi rỗng từ phần đệm để hiển thị gọn gàng hơn
true_path_clean = list(filter(None, true_path))
predicted_path_clean = list(filter(None, predicted_path))
print("\n--- Ví dụ Dự đoán ---")
# Vì sample_abstract bây giờ là một danh sách có một mục, truy cập nó bằng [0]
print(f"Tóm tắt:\n'{sample_abstract[0][:400]}...'")
print("\n" + "="*25)
print(f"✅ Đường dẫn Danh mục Đúng:\t{true_path_clean}")
print(f"🤖 Đường dẫn Danh mục Dự đoán:\t{predicted_path_clean}")
# Đánh giá hiệu suất của mô hình trên toàn bộ tập kiểm tra
print("\nĐang đánh giá trên toàn bộ tập kiểm tra...")
# Phương thức predict hoạt động chính xác với mảng NumPy đầy đủ
y_pred = pipeline.predict(X_test_text)
h_f1_score = f1(y_test, y_pred)
print(f"\nTổng điểm F1 Phân cấp trên Tập kiểm tra: {h_f1_score:.4f}")