
III.2b Ví dụ: lựa chọn đặc trưng tiến
Lựa chọn đặc trưng tiến bắt đầu với một mô hình trống và thêm các đặc trưng từng cái một. Ở mỗi bước, đặc trưng cải thiện hiệu suất mô hình nhiều nhất sẽ được… III.2b Ví dụ: lựa chọn đặc trưng tiến
Lựa chọn đặc trưng tiến bắt đầu với một mô hình trống và thêm các đặc trưng từng cái một. Ở mỗi bước, đặc trưng cải thiện hiệu suất mô hình nhiều nhất sẽ được… III.2b Ví dụ: lựa chọn đặc trưng tiến
Label Encoder là một kỹ thuật trong tiền xử lý dữ liệu (data preprocessing) dùng để chuyển đổi các nhãn hoặc dữ liệu dạng chữ (categorical data) thành dạng số (numerical data). Các mô hình… Label Encoder là gì? Ví dụ code Python
Lựa chọn đặc trưng từng bước là một phương pháp có hệ thống để xác định các đặc trưng quan trọng nhất cho một mô hình dự đoán bằng cách kết hợp cả hai kỹ… Ví dụ từng bước về lựa chọn đặc trưng từng bước (stepwise feature selection) sử dụng R bình phương hiệu chỉnh
Tuyệt! Dưới đây là một ví dụ hồi quy logistic trong R sử dụng bộ dữ liệu mtcars, một bộ dữ liệu rất phổ biến chứa thông tin về các loại xe. 🎯 Mục tiêu:… Ví dụ về hồi quy Logistic trong R trên bộ dữ liệu mtcars
🌀 Trong ví dụ với dữ liệu mô phỏng này, ta sẽ dùng SVM với kernel RBF để phân loại hai lớp có dạng vòng tròn chồng nhau – bài toán không tuyến tính. Mô… Ví dụ về SVM với kernel RBF trong Python
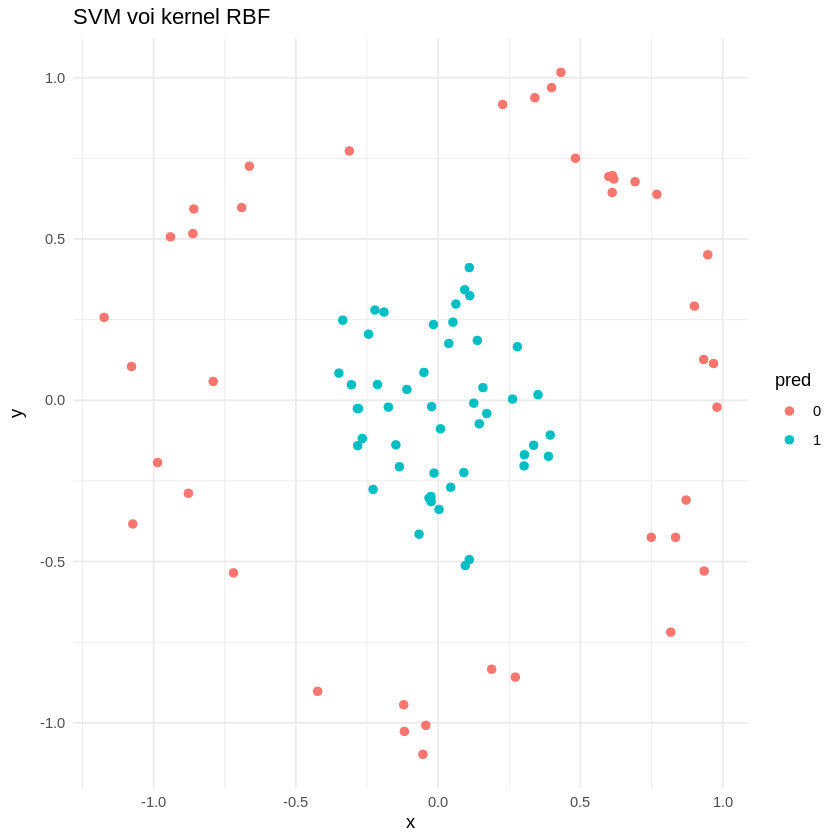
Trong ví dụ này, chúng ta sử dụng mô hình SVM với kernel RBF để phân loại hai lớp dữ liệu giả dạng vòng tròn không tuyến tính, thể hiện rõ khả năng xử lý… mô hình SVM với kernel RBF trong R
Trong ví dụ này, chúng ta sẽ sử dụng thuật toán K-Nearest Neighbors (KNN) trong thư viện scikit-learn để phân loại hoa trong bộ dữ liệu Iris. Dưới đây là chi tiết các bước: 🌸… K-Nearest Neighbors trong Python
Mặc dù đơn giản và trực quan, KNN cũng có những hạn chế đáng kể cần được cân nhắc kỹ lưỡng khi lựa chọn thuật toán cho một bài toán cụ thể. Bảng 2: Tóm… Ưu và Nhược điểm của KNN
Việc lựa chọn thuật toán học máy phù hợp là một quyết định quan trọng, phụ thuộc vào đặc điểm của dữ liệu và yêu cầu cụ thể của bài toán. KNN, với tính đơn… So sánh KNN với các thuật toán học máy khác
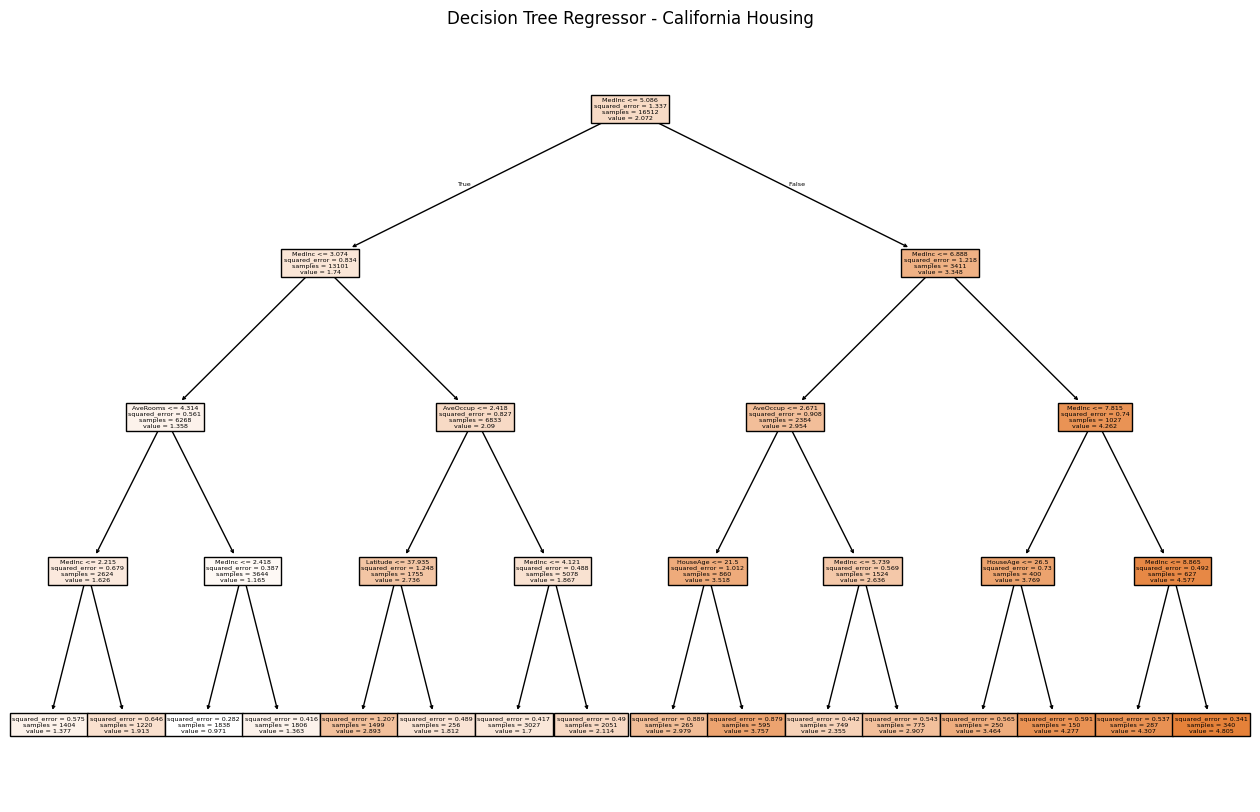
🍀 Ví dụ cây quyết định hồi quy (Decision Tree Regression) với Python: khi bài toán không phải phân loại mà là dự đoán giá trị số (như giá nhà, nhiệt độ…). Dưới đây là… Ví dụ cây quyết định hồi quy (Decision Tree Regression) với Python
Hồi quy Elastic Net – nghe tên đã thấy “đàn hồi”, đúng không? Nó kết hợp sức mạnh của cả hai cao bồi Lasso và nhạc trưởng Ridge để tạo ra một mô hình vừa… Hồi quy Elastic Net
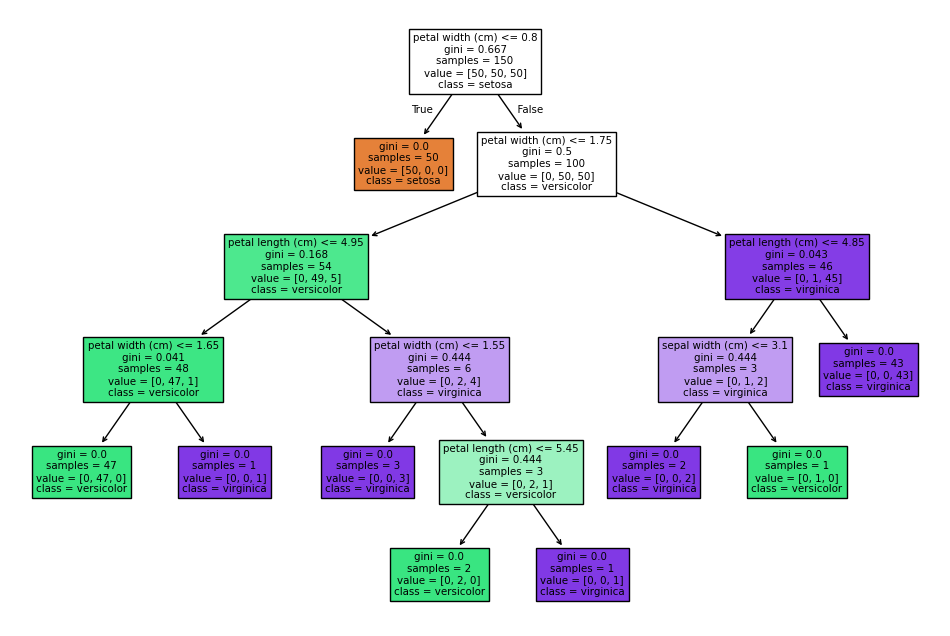
🌳 Cây Quyết Định (Decision Tree) là một thuật toán học máy phổ biến dùng để phân loại hoặc hồi quy. Nó hoạt động bằng cách chia dữ liệu thành các nhánh dựa trên điều… Ví dụ: Cây Quyết Định (Decision Tree) cho bài toán phân loại trong Python
Trong ví dụ này, chúng ta sẽ sử dụng thuật toán K-Nearest Neighbors (KNN) để phân loại hoa từ tập dữ liệu Iris. Dưới đây là phần giải thích chi tiết từng bước: 📦 1.… K-Nearest Neighbors (KNN) trong R
Bias và Variance là gì? Trong máy học, bias và variance là hai nguồn chính gây ra sai số trong dự đoán của mô hình. Chúng phản ánh cách mô hình khớp với dữ liệu… Bias và Variance trade off (cân bằng giữa độ chệch và phương sai) là gì?
Nhiễu dữ liệu (data noise) là các sai lệch, lỗi hoặc thông tin không chính xác, không liên quan trong tập dữ liệu, làm giảm chất lượng dữ liệu và ảnh hưởng đến hiệu quả… Nhiễu dữ liệu
Phân cụm K-Means là một thuật toán học máy không giám sát được sử dụng rộng rãi, được thiết kế để nhóm các điểm dữ liệu chưa được gán nhãn vào các nhóm hoặc cụm… Ứng dụng Thực tế của Thuật toán Phân cụm K-Means trong Phân tích Dữ liệu và Kinh doanh
SVM là một thuật toán mạnh mẽ, nhưng việc hiểu vị trí của nó so với các thuật toán học máy khác là rất quan trọng để lựa chọn mô hình phù hợp cho một… So sánh SVM với các Thuật toán Học máy Khác