
Xác thực chéo (cross validation) với K = 3
Xác thực chéo giống như việc bạn kiểm tra một học sinh bằng nhiều bài kiểm tra khác nhau để đảm bảo học sinh đó thực sự hiểu bài, chứ không chỉ học vẹt một… Xác thực chéo (cross validation) với K = 3
Xác thực chéo giống như việc bạn kiểm tra một học sinh bằng nhiều bài kiểm tra khác nhau để đảm bảo học sinh đó thực sự hiểu bài, chứ không chỉ học vẹt một… Xác thực chéo (cross validation) với K = 3

Siêu tham số giống như những quy tắc trước khi huấn luyện một đội bóng: chọn chiến thuật, thời gian tập luyện, ăn kiêng,… Nếu chọn sai, cả đội chơi như gà mắc tóc. Tối… tìm kiếm ngẫu nhiên để tối ưu siêu tham số
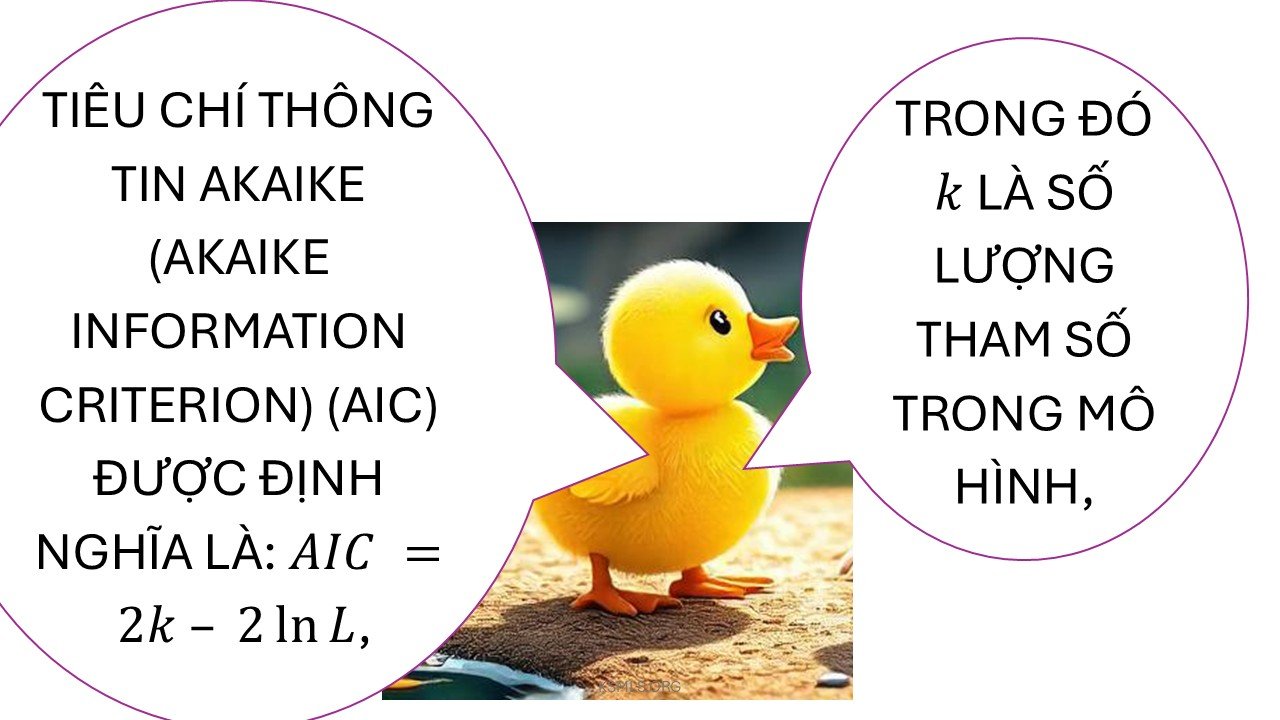
AIC được tính như sau: Trong đó: 👉 Mô hình nào có AIC thấp nhất sẽ được trao vương miện 🎖️ 🎬 Ví dụ vui Bạn có 3 mô hình dự đoán điểm… Tiêu chí thông tin Akaike Information Criterion (AIC)

🎯 BIC (Bayesian Information Criterion) là “phiên bản nghiêm khắc hơn của AIC” trong việc chọn mô hình thống kê! 🧠 BIC là gì? Hãy tưởng tượng bạn đang tuyển chọn mô hình cho một… Tiêu chí BIC (Bayesian Information Criterion)
Bạn tưởng tượng có một bữa tiệc với 2 nhóm khách mời: nhóm “Mèo” và nhóm “Chó”. Nhiệm vụ của bạn là tìm một đường ranh giới (siêu phẳng) để phân chia hai nhóm này… Máy véc tơ hỗ trợ (SVM) – Vừa thông minh vừa biết “giữ kẽ”!

Học máy, một nhánh quan trọng thuộc trí tuệ nhân tạo (AI), được định nghĩa là khả năng của các hệ thống máy tính trong việc học hỏi và cải thiện từ các trải nghiệm… Những ứng dụng của học máy

Ưu điểm: dễ hiểu, cung cấp cái nhìn nhanh về độ phù hợp của mô hình.Hạn chế: Ví dụ Đánh giá mô hình: cao (SSR lớn, SSE nhỏ) cho thấy mô hình tốt. Trong ví… Tính chất của hệ số xác định

Học không có giám sát giống như thám tử tự mò mẫm manh mối mà không có ai chỉ dẫn. Đôi khi nó tìm ra những điều bất ngờ mà chính bạn cũng không nghĩ… Học không có giám sát

Trong học máy, khả năng khái quát hóa (generalization) là năng lực của mô hình dự đoán chính xác trên dữ liệu chưa từng thấy — không chỉ “học thuộc lòng” dữ liệu huấn luyện… khả năng khái quát hóa

📊 MSE, MAE và RMSE là ba tiêu chí phổ biến dùng để đánh giá độ chính xác của mô hình hồi quy hoặc dự báo. Mỗi tiêu chí có cách đo lường sai số… Tiêu chí đánh giá: MSE, MAE, RMSE
📐 Thiết lập dạng ma trận cho hồi quy đa biến là cách biểu diễn mô hình hồi quy tuyến tính nhiều biến dưới dạng đại số tuyến tính, giúp việc tính toán và ước… Thiết lập dạng ma trận cho hồi quy đa biến
Siêu tham số là gì? Đó là những “bí kíp võ công” bạn phải set sẵn trước khi cho mô hình học máy “luyện công” (huấn luyện). Không giống trọng số tự học từ dữ… Siêu tham số là gì?

Hồi quy Ridge, anh bạn thân của Lasso, cũng là một “cao bồi” trong thế giới hồi quy, nhưng tính cách thì… hiền lành hơn một chút! Nếu Lasso là chàng cao bồi vung dây… hồi quy Ridge
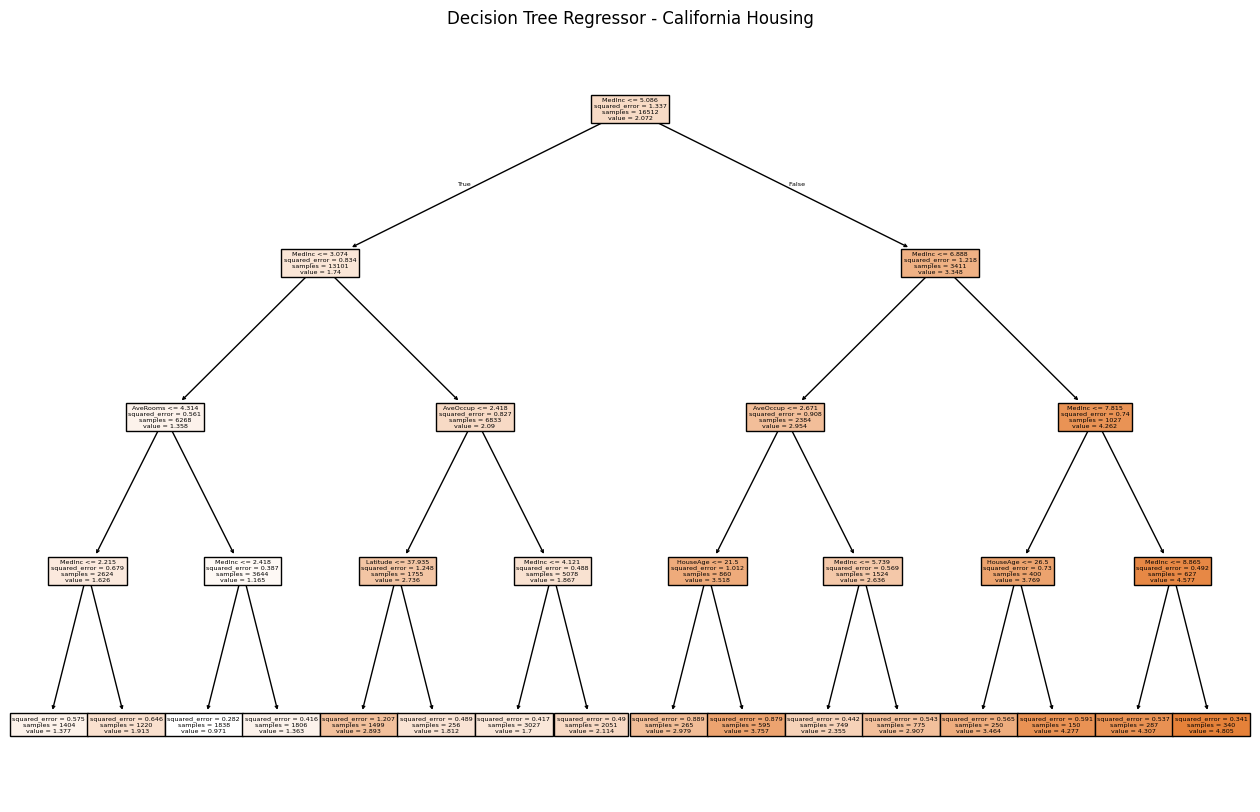
🍀 Ví dụ cây quyết định hồi quy (Decision Tree Regression) với Python: khi bài toán không phải phân loại mà là dự đoán giá trị số (như giá nhà, nhiệt độ…). Dưới đây là… Ví dụ cây quyết định hồi quy (Decision Tree Regression) với Python

Hãy tưởng tượng bạn đang ở một khu vui chơi, và nhiệm vụ của bạn là ném vòng vào các cột để giành giải thưởng. Nhưng thay vì ném vòng một cách ngẫu nhiên, bạn… hồi quy đa thức
Hồi quy Elastic Net – nghe tên đã thấy “đàn hồi”, đúng không? Nó kết hợp sức mạnh của cả hai cao bồi Lasso và nhạc trưởng Ridge để tạo ra một mô hình vừa… Hồi quy Elastic Net

🎓 Hồi quy đa biến là gì? Hãy tưởng tượng bạn là một đạo diễn phim 🎬 đang lựa chọn dàn diễn viên cho bộ phim “Dự đoán điểm thi cuối kỳ”. Diễn viên chính:… Hồi quy đa biến là gì
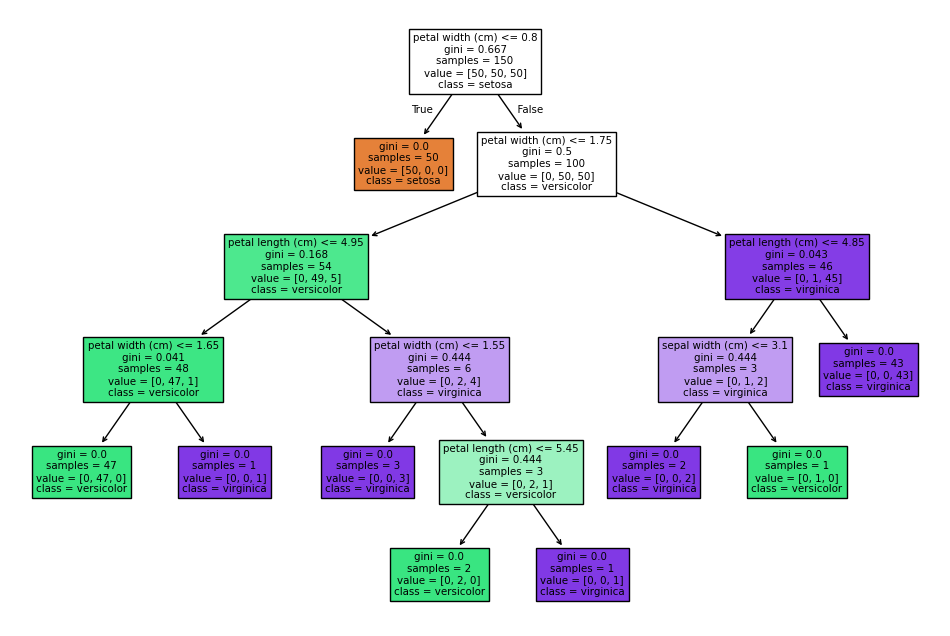
🌳 Cây Quyết Định (Decision Tree) là một thuật toán học máy phổ biến dùng để phân loại hoặc hồi quy. Nó hoạt động bằng cách chia dữ liệu thành các nhánh dựa trên điều… Ví dụ: Cây Quyết Định (Decision Tree) cho bài toán phân loại trong Python
LỰA CHỌN LÙI (Backward Selection) – “biệt đội đã full người, giờ phải loại bớt” Giả sử bạn đang quản lý một biệt đội siêu nhân đông đúc, kiểu: “Càng đông càng mạnh” – bạn… Lựa Chọn Lùi –Chọn Người Để “Đuổi Việc”
Bạn có bao giờ gặp tình huống dữ liệu nhiều chiều đến mức… chóng mặt? Nói cách khác là dữ liệu “thừa mỡ”? Đưa PCA xử lý giúp – giữ lại cái chất, bỏ đi… Principal Component Analysis – Phân tích thành phần chính – giải pháp cho dữ liệu thừa mỡ

Hệ số xác định — hay còn gọi là R bình phương (R²) — chính là “bài kiểm tra độ tin cậy” của mô hình hồi quy, kiểu như mô hình có làm tốt việc… Hệ số xác định

Trong hồi quy, ta hay nghe tới tổng bình phương – như thể đây là món “gia vị” không thể thiếu trong món ăn thống kê. Nhưng mà tổng bình phương thì cũng có… họ… Các loại Tổng bình phương (Sum of Squares)
Trong ví dụ này, chúng ta sẽ sử dụng thuật toán K-Nearest Neighbors (KNN) để phân loại hoa từ tập dữ liệu Iris. Dưới đây là phần giải thích chi tiết từng bước: 📦 1.… K-Nearest Neighbors (KNN) trong R
Trong thế giới dữ liệu, K-means giống như một cuộc dạo chơi đi tìm bạn thân theo sở thích thầm kín mà không cần nói ra. Bạn cứ lặng lẽ xếp vào nhóm có đặc… Phân cụm K-Means + code Python và R
Hồi quy đa thức là gì?Nó giống như bạn đang cố vẽ một đường cong “mượt mà” để mô tả một đám mây điểm dữ liệu lộn xộn trên biểu đồ. Thay vì dùng một… Hồi quy đa thức
Hãy tưởng tượng bạn đang tuyển người yêu. Có cả trăm người ứng tuyển, mỗi người đều có “đặc trưng” riêng: cao, thấp, biết nấu ăn, thích xem phim, mê thể thao, yêu mèo, ghét… Lựa Chọn Đặc Trưng – Như Tìm Người Yêu Lý Tưởng

Học có giám sát giống như có một “thầy giáo” nghiêm khắc đứng bên cạnh, luôn sửa sai khi bạn làm bài tập. Nhưng khi “thầy” đi vắng (gặp dữ liệu mới), bạn phải tự… Học có giám sát
Hãy tưởng tượng dữ liệu của bạn là một đám đông đang chen chúc trong một buổi hòa nhạc rock. Có đứa thì hét to kinh khủng (giá trị lớn), có đứa thì thì thầm… Phép biến đổi log là gì?

Hãy tưởng tượng bạn đang huấn luyện một chú mèo để làm xiếc, như nhảy qua vòng lửa. Tập huấn luyện (Training set): Đây là phần “bí kíp” bạn dùng để dạy chú mèo. Bạn… phân chia tập huấn luyện – tập kiểm tra
Bias và Variance là gì? Trong máy học, bias và variance là hai nguồn chính gây ra sai số trong dự đoán của mô hình. Chúng phản ánh cách mô hình khớp với dữ liệu… Bias và Variance trade off (cân bằng giữa độ chệch và phương sai) là gì?
Nhiễu dữ liệu (data noise) là các sai lệch, lỗi hoặc thông tin không chính xác, không liên quan trong tập dữ liệu, làm giảm chất lượng dữ liệu và ảnh hưởng đến hiệu quả… Nhiễu dữ liệu
