
I.3 Học không có giám sát
Học không có giám sát giống như thám tử tự mò mẫm manh mối mà không có ai chỉ dẫn. Đôi khi nó tìm ra những điều bất ngờ mà chính bạn cũng không nghĩ… I.3 Học không có giám sát
Học không có giám sát giống như thám tử tự mò mẫm manh mối mà không có ai chỉ dẫn. Đôi khi nó tìm ra những điều bất ngờ mà chính bạn cũng không nghĩ… I.3 Học không có giám sát

Học có giám sát giống như có một “thầy giáo” nghiêm khắc đứng bên cạnh, luôn sửa sai khi bạn làm bài tập. Nhưng khi “thầy” đi vắng (gặp dữ liệu mới), bạn phải tự… I.2-Học có giám sát

Học máy, một nhánh quan trọng thuộc trí tuệ nhân tạo (AI), được định nghĩa là khả năng của các hệ thống máy tính trong việc học hỏi và cải thiện từ các trải nghiệm… I.1-Những ứng dụng của học máy

Trong bài đăng này, chúng ta sẽ nói về phương pháp chưng cất tri thức dựa trên đặc trưng. Một trong những bài báo tiên phong là “FitNets: Hints for Thin Deep Nets” (FitNets: Gợi… Chưng cất tri thức dựa trên đặc trưng (feature-based distillation) trong Pytorch

Ví dụ này minh họa về Chưng cất Tri thức (Knowledge Distillation), một kỹ thuật mà một mô hình “học trò” (student) nhỏ được huấn luyện để bắt chước một mô hình “thầy” (teacher) lớn… Ví dụ: Chưng cất Tri thức (Knowledge Distillation) trong PyTorch trên MNIST
Rust là ngôn ngữ lập trình hệ thống hiện đại, nổi bật với hiệu năng cao, an toàn bộ nhớ và khả năng xử lý đồng thời vượt trội. Giới thiệu về Rust Rust là… Rust trong phát triển phần mềm AI
Cách nghĩ đơn giản nhất về điều này là: Hãy coi MRI như một bức ảnh có độ phân giải cao của não, cho bạn thấy chính xác nó trông như thế nào. fMRI giống… Sự khác biệt giữa MRI và fMRI
Việc ứng dụng trí tuệ nhân tạo (AI) trong y tế, đặc biệt là trong hình ảnh y khoa, hứa hẹn sẽ cải thiện đáng kể việc phát hiện, chẩn đoán và điều trị các… Thư viện MONAI cho Phân Tích Ảnh Não
Mô hình khuếch tán (diffusion model) là một loại mô hình taọ sinh, có khả năng tạo ra dữ liệu mới, chẳng hạn như hình ảnh, bằng cách học cách đảo ngược một quá trình… Mô hình khuếch tán (diffusion model)
Label Encoder là một kỹ thuật trong tiền xử lý dữ liệu (data preprocessing) dùng để chuyển đổi các nhãn hoặc dữ liệu dạng chữ (categorical data) thành dạng số (numerical data). Các mô hình… Label Encoder là gì? Ví dụ code Python
Hàm mất mát tri giác (perceptual loss) là một loại hàm mất mát được sử dụng trong Computer vision, đặc biệt cho các tác vụ như tạo hoặc thay đổi hình ảnh. Thay vì so… Hàm mất mát tri giác (perceptual loss)
Được phát triển bởi João Moura, crewAI cung cấp một môi trường có cấu trúc để điều phối các tác nhân AI tự trị, cho phép chúng hợp tác và giải quyết các nhiệm vụ… Điều phối các Tác nhân AI Hợp tác cho các Nhiệm vụ Phức tạp bằng crewAI và Ollama
Việc chạy các mô hình ngôn ngữ lớn (LLM) cục bộ trên laptop ngày càng trở nên khả thi, và Ollama giúp cho việc này trở nên dễ dàng hơn. Chìa khóa để có trải… Các mô hình LLM có thể trên laptop với Ollama
Trong lĩnh vực khoa học dữ liệu và thống kê, việc xử lý dữ liệu bị thiếu hay “điền khuyết” là một bước tiền xử lý quan trọng, ảnh hưởng trực tiếp đến chất lượng… MissForest và Nội suy Thống kê: So sánh hai phương pháp điền khuyết dữ liệu
RAG là gì? RAG là viết tắt của Retrieval-Augmented Generation, có nghĩa là Tạo sinh Tăng cường bằng Truy xuất. Đây là một kỹ thuật mạnh mẽ được sử dụng trong trí tuệ nhân tạo… RAG là gì?
LangChain là một framework mã nguồn mở được thiết kế để đơn giản hóa việc tạo ra các ứng dụng được vận hành bởi các mô hình ngôn ngữ lớn (LLM). Có sẵn cho cả… LangChain: Nguồn Sức Mạnh Đằng Sau Các Ứng Dụng Ngôn Ngữ Thông Minh

LlamaIndex là một framework dữ liệu mã nguồn mở mạnh mẽ và linh hoạt được thiết kế để kết nối các nguồn dữ liệu tùy chỉnh với các mô hình ngôn ngữ lớn (LLM). Về… LlamaIndex: cầu nối giữa dữ liệu của bạn và các Mô hình Ngôn ngữ Lớn

Trong thế giới trí tuệ nhân tạo đang phát triển nhanh chóng, các Mô hình Ngôn ngữ Lớn (LLM) đã nổi lên như những công cụ mạnh mẽ có khả năng tạo ra văn bản… Bóng Ma Trong Cỗ Máy: Tìm Hiểu Về “Ảo Giác” Trong Các Mô Hình Ngôn Ngữ Lớn

Retrieval‑Augmented Generation (RAG) là một kỹ thuật mạnh mẽ giúp mở rộng khả năng của các mô hình ngôn ngữ lớn (LLMs) bằng cách kết nối chúng với các nguồn kiến thức bên ngoài.Theo Google Developer… Sử dụng Retrieval‑Augmented Generation (RAG) cùng EmbeddingGemma với Ollama trong Python
Ollama là một công cụ mã nguồn mở mạnh mẽ và tiện lợi, cho phép người dùng dễ dàng tải về, cài đặt và chạy các mô hình ngôn ngữ lớn (LLM) ngay trên máy… Ollama: Chạy các mô hình ngôn ngữ lớn ngay trên máy tính của bạn

Thuật toán MissForest là một phương pháp imputation (điền khuyết) dữ liệu mạnh mẽ, dựa trên thuật toán Random Forest (Rừng Ngẫu nhiên) để ước tính và điền vào các giá trị bị thiếu trong… Thuật toán Nhớ Rừng (MissForest) cho điền khuyết dữ liệu + code Python

Nếu bạn nào thích bài thơ Nhớ Rừng của Thế Lữ thì nên tìm hiểu về thuật toán Nhớ Rừng (MissForest) 😊! Thuật toán MissForest là một phương pháp imputation (điền khuyết) dữ liệu bị… Thuật toán Nhớ Rừng (MissForest) để điền khuyết dữ liệu + code R

Bạn mệt mỏi với thời gian huấn luyện mô hình kéo dài? Khám phá phương pháp “progressive resizing” – một kỹ thuật đơn giản giúp tăng tốc huấn luyện, cải thiện độ chính xác và tiết kiệm tài nguyên. Hãy tìm hiểu cách bắt đầu với ảnh nhỏ để đạt được kết quả lớn.
Lựa chọn đặc trưng từng bước là một phương pháp có hệ thống để xác định các đặc trưng quan trọng nhất cho một mô hình dự đoán bằng cách kết hợp cả hai kỹ… Ví dụ từng bước về lựa chọn đặc trưng từng bước (stepwise feature selection) sử dụng R bình phương hiệu chỉnh
Trong bài toán học máy, khi dữ liệu bị mất cân bằng (imbalanced data), mô hình có xu hướng thiên lệch về phía lớp chiếm đa số. Một cách phổ biến để giải quyết vấn… sử dụng hàm mất mát tùy chỉnh cho dữ liệu mất cân bằng
NearMiss là một nhóm các thuật toán lấy mẫu thiếu (undersampling) được thiết kế để xử lý dữ liệu mất cân bằng. Khác với SMOTE tạo ra các mẫu mới cho lớp thiểu số, NearMiss… NearMiss: lấy mẫu thiếu cho dữ liệu mất cân bằng + Python code
SMOTE là viết tắt của Synthetic Minority Over-sampling Technique (Kỹ thuật Lấy Mẫu Quá Mức Tổng Hợp cho Lớp Thiểu Số). Trong học máy, chúng ta thường gặp phải dữ liệu mất cân bằng (imbalanced… SMOTE: Kỹ thuật Lấy Mẫu Quá Mức Tổng Hợp cho Lớp Thiểu Số + Python Code

Dữ liệu mất cân bằng, nơi một lớp chiếm số lượng lớn hơn đáng kể so với (các) lớp khác, là một thách thức phổ biến trong học máy. Tình trạng này có thể dẫn… Các Phương Pháp Cho Dữ Liệu Mất Cân Bằng
Trong lĩnh vực học máy, vấn đề dữ liệu mất cân bằng là một thách thức phổ biến và nghiêm trọng, thường xuyên xuất hiện trong các bộ dữ liệu thực tế. Tình trạng này… Cải thiện dữ liệu mất cân bằng trong học máy bằng phương pháp trọng số lớp
Tuyệt! Dưới đây là một ví dụ hồi quy logistic trong R sử dụng bộ dữ liệu mtcars, một bộ dữ liệu rất phổ biến chứa thông tin về các loại xe. 🎯 Mục tiêu:… Ví dụ về hồi quy Logistic trong R trên bộ dữ liệu mtcars
Trong số các kiến trúc học không giám sát, Autoencoder (AE) nổi lên như một công cụ mạnh mẽ để học biểu diễn dữ liệu. Một autoencoder là một loại mạng nơ-ron nhân tạo được… Autoencoder, Stacked Autoencoder và Ứng dụng
🌀 Trong ví dụ với dữ liệu mô phỏng này, ta sẽ dùng SVM với kernel RBF để phân loại hai lớp có dạng vòng tròn chồng nhau – bài toán không tuyến tính. Mô… Ví dụ về SVM với kernel RBF trong Python
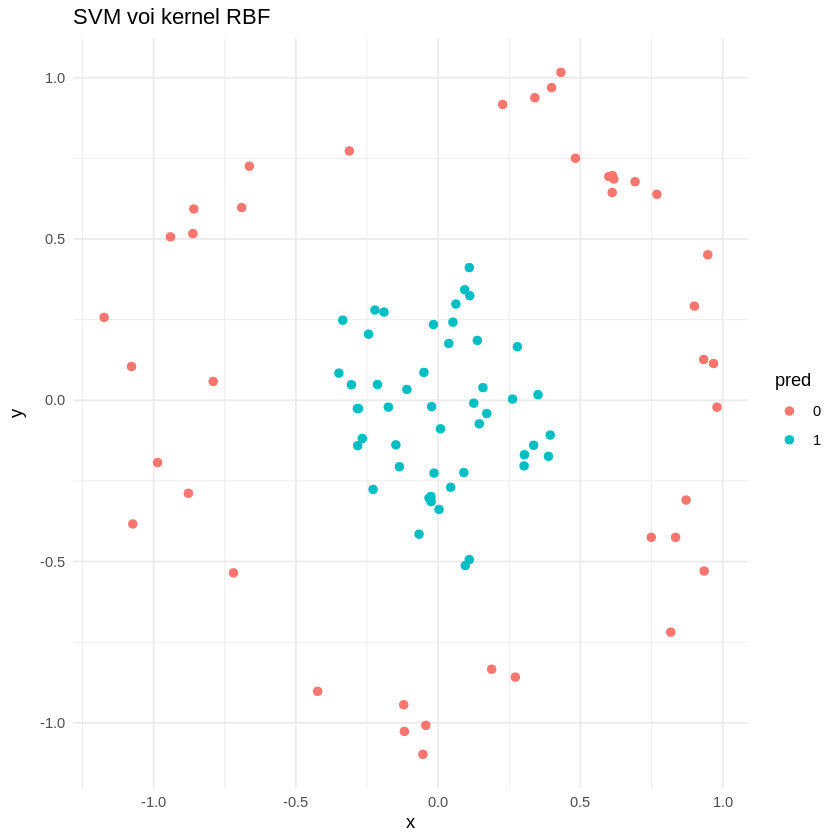
Trong ví dụ này, chúng ta sử dụng mô hình SVM với kernel RBF để phân loại hai lớp dữ liệu giả dạng vòng tròn không tuyến tính, thể hiện rõ khả năng xử lý… mô hình SVM với kernel RBF trong R
Trong ví dụ này, chúng ta sẽ sử dụng thuật toán K-Nearest Neighbors (KNN) trong thư viện scikit-learn để phân loại hoa trong bộ dữ liệu Iris. Dưới đây là chi tiết các bước: 🌸… K-Nearest Neighbors trong Python